Kapitel 9 Visualisierung
Es hat ein bisschen gedauert, aber wir mussten uns zuerst erarbeiten, wie wir eigentlich in R mit Daten umgehen können und grob verstehen wie sich R überhaupt verhält, bis wir endlich was spaßiges machen können.
Und Datenvisualisierung ist vermutlich so ziemlich das spaßigste, was wir in R anstellen können. Eine gute Visualisierung (Plot) ist aussagekräftigter als jede schnöde Tabelle, kann unintuitive Zusammenhänge aufdecken und die Interpretation eurer Daten deutlich vereinfachen.
Deswegen ist der erste Schritt jeder Datenanalyse ein Plot der Daten in verschiedenen Formen um ein Gefühl für die Struktur und die Zusammenhänge dieser Daten zu bekommen.
9.1 ggplot2
ggplot2 ist nicht nur ein R-Packages, es ist auch gleichzeitig eine Implementation des Grammar of Graphics. Das klingt fancy (ist es auch), heißt für uns aber in erster Linie nur, dass es gut durchdachter Kram ist.
ggplot2 baut euch einen Plot aus verschiedenen Elementen zusammen, und es hilft durchaus ein grobes Gefühl dafür zu haben, wie das unter der Haube aussieht.
- geom: Jedes geom ist eine Lage des Plots, der Grundlayer ist einfach leer. Jeder weitere Layer enthält
geom-Elemente, wie Balken, Histogramme, Punkte etc. Eingeomist eine geometrische Darstellungsform, und wenn ihr mehrere Darstellungsformen übereinanderlegen wollt, erstellt ihr damit mehrere Layer. aes: Aesthetics, die Zuordnungen einer Variable mit konkreten Werten zu einem Aspekt des Plots, wie zum Beispiel “Alter auf die x-Achse, Körpergröße auf die y-Achse”.- scales: Mit scales können wir die einzelnen aesthetics bearbeiten, so können wir zum Beispiel die Abstände auf der x-Achse anpassen oder die Beschriftung auf der y-Achse.
- theme: Optional können wir jedes optische Element des Plots manuell anpassen, sei es die Schriftart im Titel oder die Farbe des Hintergrunds, die Position der Legende.
Ein Beispiel:
ggplot(data = qmsurvey, aes(x = alter, y = feiern)) +
geom_col() +
scale_y_continuous(breaks = seq(0, 100, 15), minor_breaks = seq(0, 100, 5)) +
labs(title = "Alter und Feiern",
subtitle = "Wie oft gehst du im Monat feiern",
x = "Alter (Jahre)", y = "Tage pro Monat")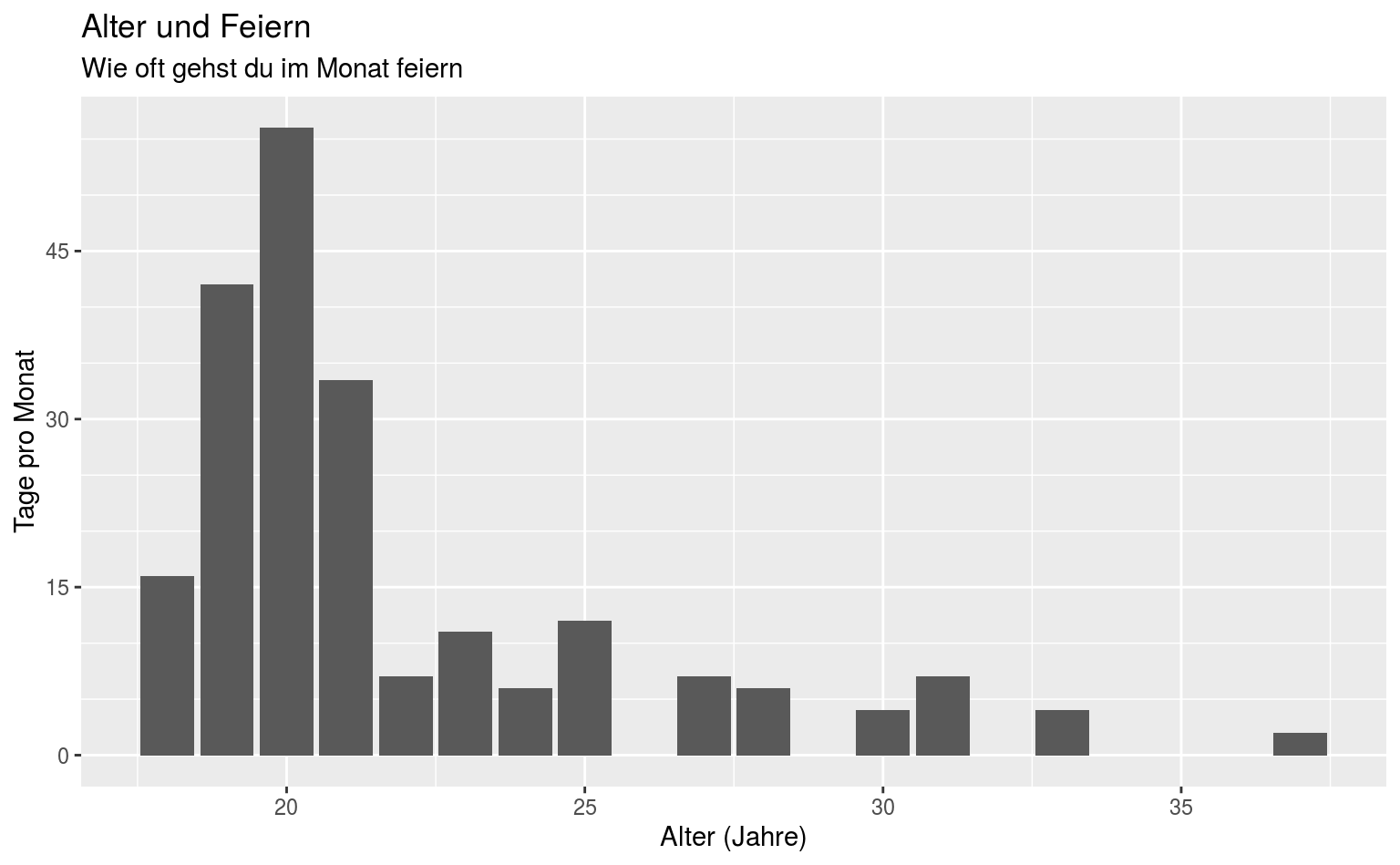
Okay, was haben wir da gemacht?
ggplot() macht erstmal einen neuen Plot auf. Mit data = qmsurvey sagen wir, mit welchem Datensatz wir arbeiten, und wo ggplot die Namen der Variablen suchen soll, die wir benutzen. aes() macht die Verknüpfung von Skalen (x, y) zu Variablen, soweit alles erwartungsgemäß, kein fancy Voodoo, nur gewöhnungsbedürftiger Syntax.
geom_col macht ein Balkendiagramm auf, und wir haben ja bereits definiert welche Variable wo hin soll.
In scale_y_continuous sagen wir jetzt noch, dass die Achsenabstände in 15er-Schritten liegen sollen, und wir kleinere Abstände (die dünneren weißen Linien) in 5er-Abständen liegen sollen.
Als letztes kümmern wir uns ein bisschen um die Kosmetik: Wir beschriften unsere Elemente mit labs(), wobei wir Title, Untertitel und Achsen beschreiben.
Im Folgenden kommen einige Beispiele, aber grundsätzlich könnt ihr euch alles auch auf der offiziellen Seite unter http://ggplot2.tidyverse.org anschauen, wo es auch eine Referenz aller Funktionen mit Anwendungsbeispielen gibt. Ich für meinen Teil habe am Anfang (und auch immer noch) viel Zeit damit verbracht, die Referenz nach etwas zu durchsuchen, dass so grob nach dem aussieht, was ich gerne hätte – und das dann so lange zu tweaken bis es funktioniert.
Das Erfolgserlebnis nach ewigem Rungefummel ist nicht zu unterschätzen, aber natürlich ist es hilfreich, wenn man erstmal die Grundlagen erklärt bekommt.
9.2 Layer: geom_wtf
Der visuelle Kern eines Plots ist die geometrische Verknüpfung eurer Daten auf einen Layer, sowas wie Punkte, Linien, Balken, ihr wisst schon. Ein Plot braucht mindestens einen Layer (ein geom) um überhaupt irgendwas anzuzeigen, und die entsprechenden Funktionen sind dankbar einfach benannt:
geom_point: Macht Punkte (Scatterplot)geom_line: Macht Liniengeom_boxplot: Boxplotsgeom_histogram: Histogramm (Häufigkeitsverteilung)geom_bar: Balkendiagramm mit Häufigkeiten auf der y-Achsegeom_col: Balkendiagramm mit frei wählbarer y-Achse
9.2.1 Barcharts & Histogramme
Eine der einfachsten Anwendungsfälle für Visualisierungen sind Balken- und Histogramme. Der Unterschied zwischen den beiden ist eher subtil: Histogramme haben eine numerische/kontinuierliche Variable auf der x-Achse, und Barcharts haben diskrete Variablen auf der x-Achse. Daraus ergibt sich auch, dass Barcharts immer einen Balken pro Merkmalsausprägung haben.
Die y-Achse ist jeweils die Häufigkeit, mit der die jeweilige Variable auftritt. Diese wird in der Regel als absolute Häufigkeit in ggplot2 angezeigt, aber wir können auch relative Häufigkeiten oder densities verwenden.
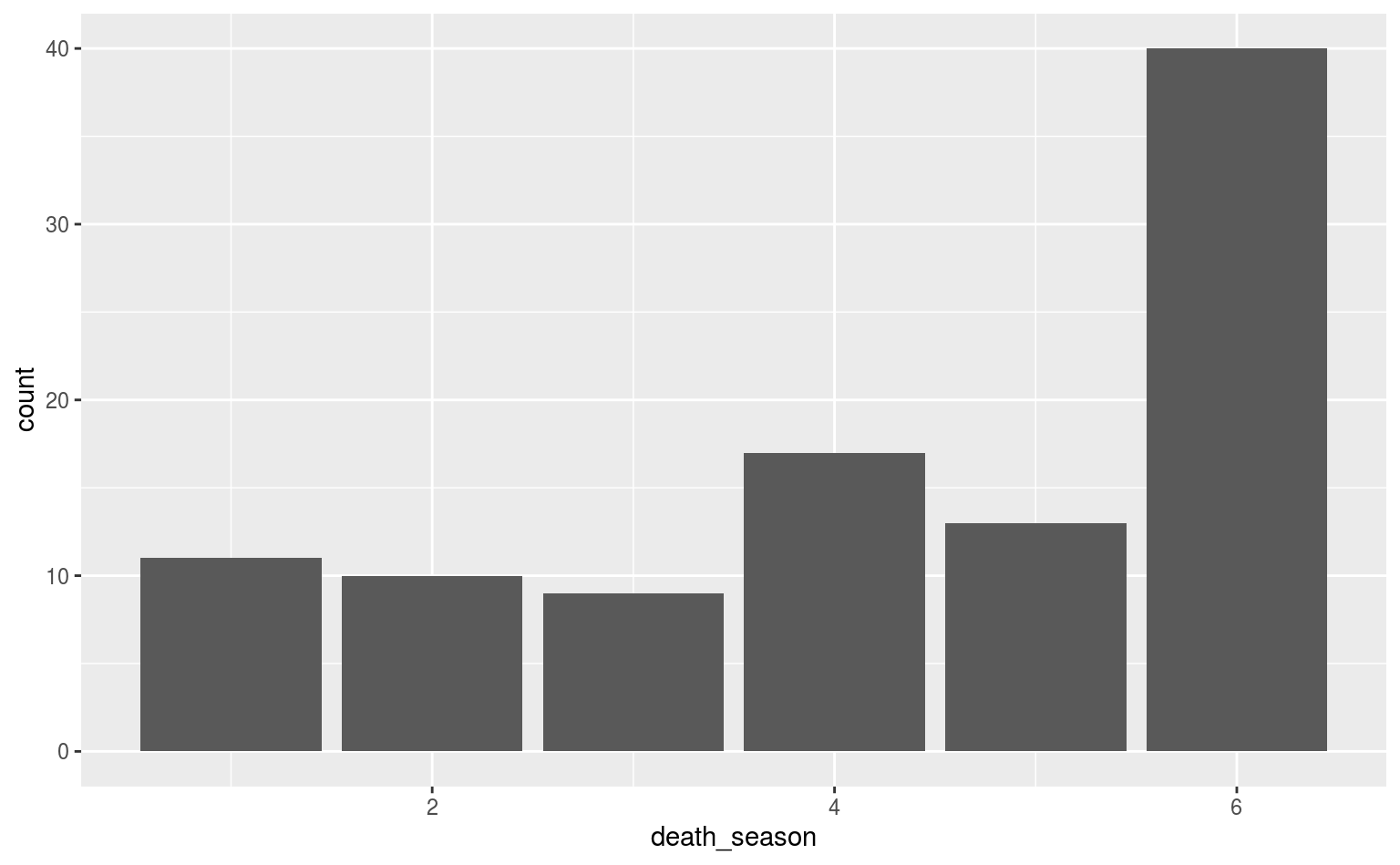
# Balken mit relativen Häufigkeiten
ggplot(data = gotdeaths, aes(x = death_season)) +
geom_bar(aes(y = ..prop..))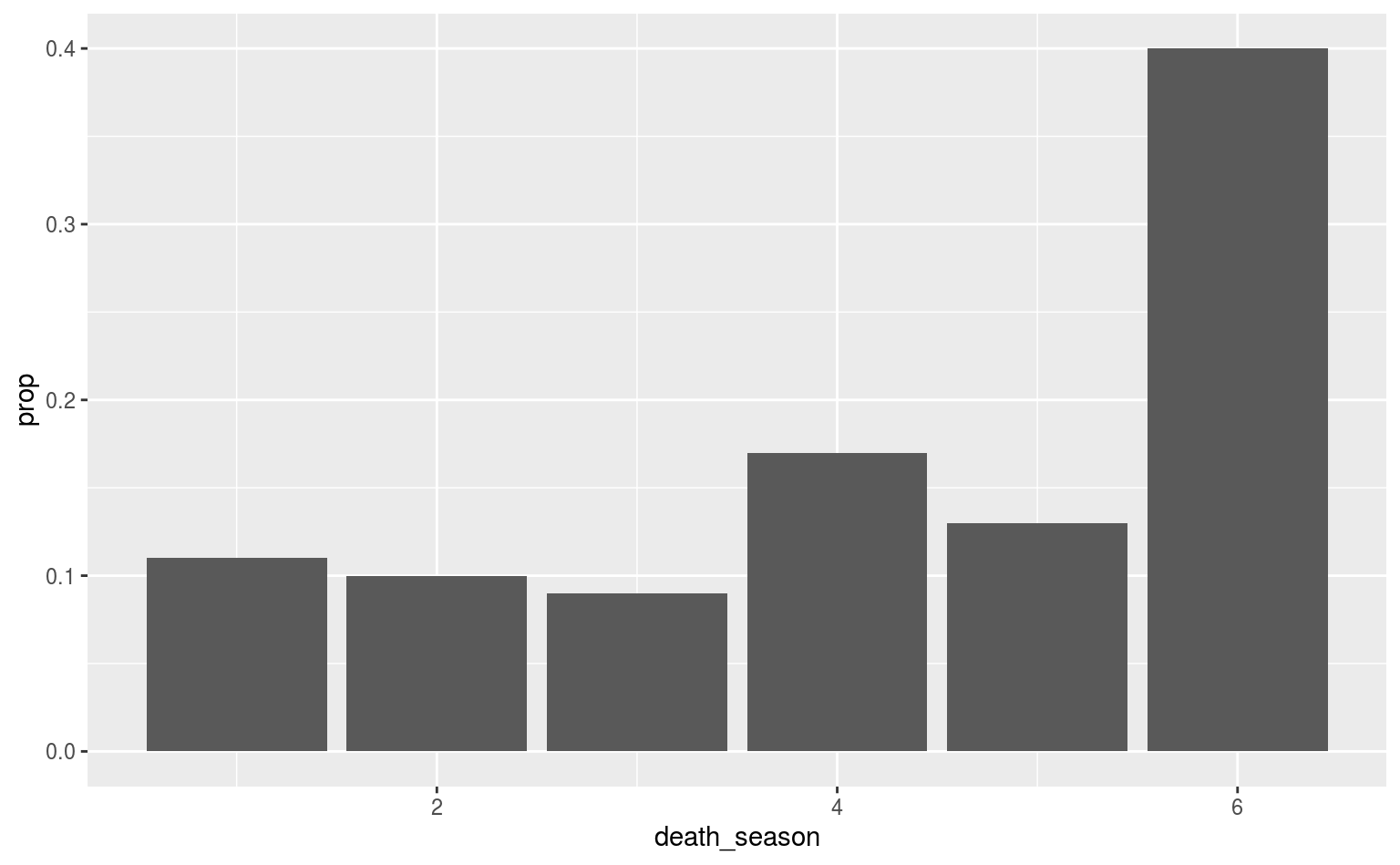
Das ist zwar schön und gut, aber es sieht noch nicht so wirklich brauchbar aus, und es fehlen vor allem aussagekräftige Beschriftungen. Letztere sind via labs() sehr einfach:
ggplot(data = gotdeaths, aes(x = death_season)) +
geom_bar() +
labs(title = "Game of Thrones: Deaths",
subtitle = "Deaths per Season",
x = "Season", y = "# of Deaths")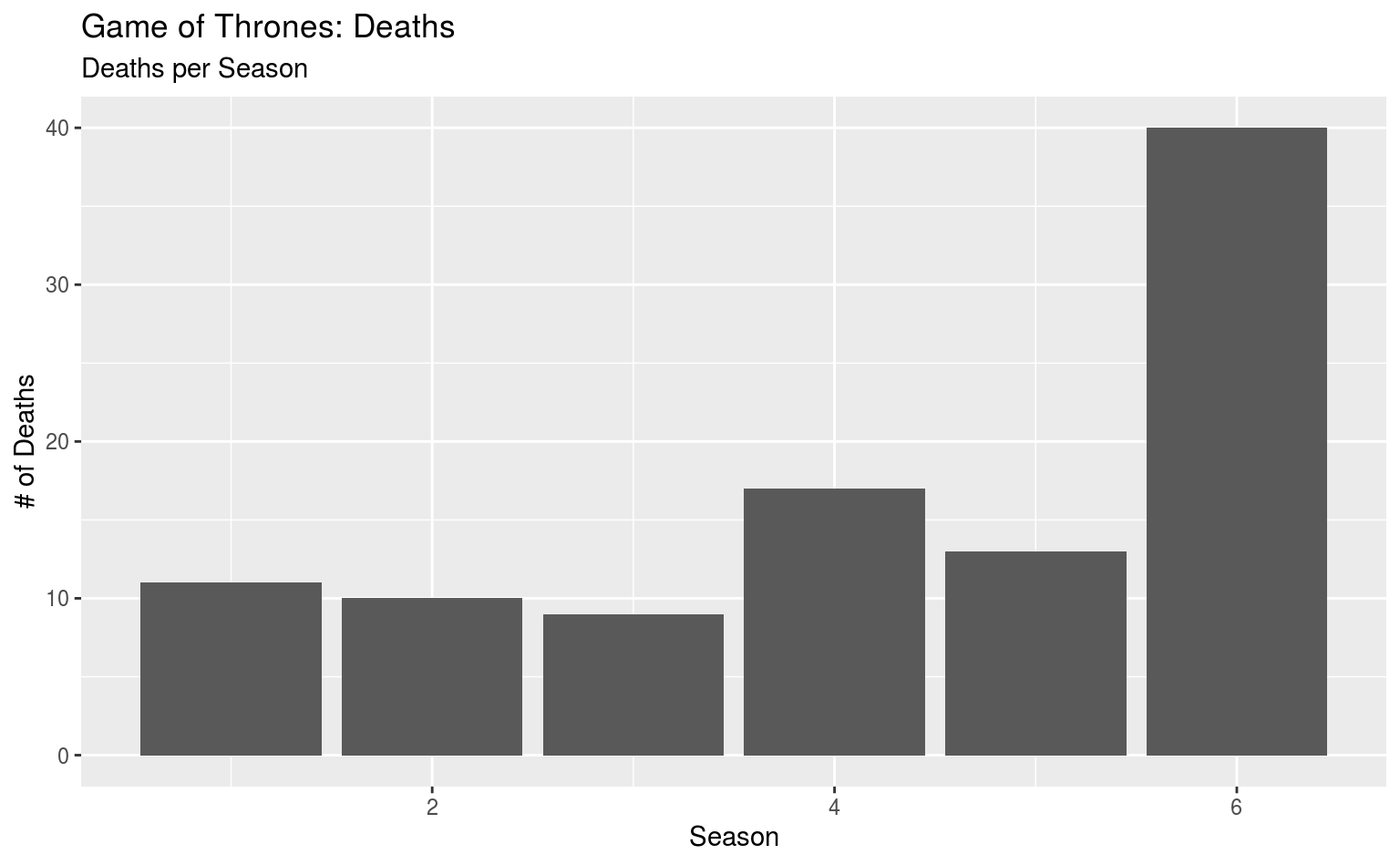
9.2.1.1 geom_bar vs. geom_col vs geom_histogram
Diese drei geoms machen ähnliche Dinge, nämlich irgendwas mit Balken(ish), aber sie sind nicht beliebig austauschbar.
In Kürze:
geom_histogram: Histogramm für numerische, stetige Variablengeom_bar: Häufigkeitsverteilung in Balkenform für diskrete Variablen (numerisch oder kategorial)geom_col: Für bivariate Plots mit einem diskreten Merkmal auf der x-Achse und einer numerischen Variable auf der y-Achse
Ein gängiger Anwendungsfall für geom_col wäre es, Häufigkeiten zu plotten, die wir vorher manuell berechnet haben. Ein Beispiel:
#> # A tibble: 7 x 4
#> # Groups: gender [3]
#> gender rauchen n prop
#> <fct> <fct> <int> <dbl>
#> 1 keine Angabe In Gesellschaft 1 1
#> 2 männlich In Gesellschaft 5 0.312
#> 3 männlich Ja 1 0.0625
#> 4 männlich Nein 10 0.625
#> 5 weiblich In Gesellschaft 12 0.141
#> 6 weiblich Ja 6 0.0706
#> 7 weiblich Nein 67 0.788Hier haben wir die relativen Häufigkeiten für die Merkmalsausprägungen in rauchen berechnet, relativ zu jeder Gruppe in gender.
Damit können wir sowas machen:
qmsurvey %>%
count(gender, rauchen) %>%
group_by(gender) %>%
mutate(prop = round(n/sum(n), 4)) %>%
ggplot(aes(x = rauchen, y = prop, fill = gender)) +
geom_col(position = "dodge", color = "black") +
scale_y_continuous(labels = scales::percent) +
labs(title = "Raucherstatus nach Gender",
subtitle = "Relative Häufigkeiten in >Gender<")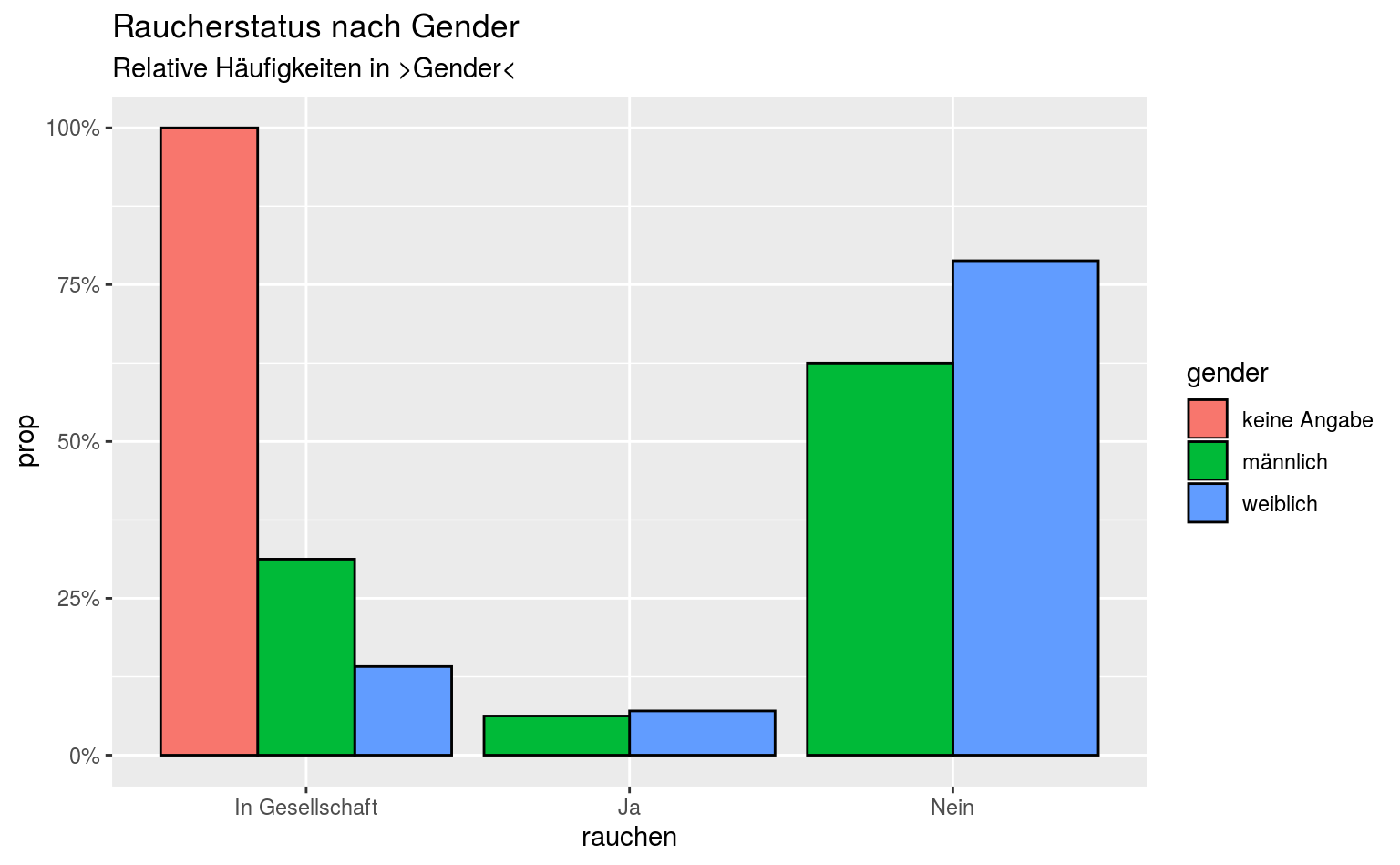
Ein klassisches Beispiel für “Daten erst präparieren, dann plotten”. Es ist viel einfacher schnell die gruppierten Prozente zu berechnen, als ggplot2 dazu zwingen zu wollen, die entsprechende Gruppierung und Berechnung zu übernehmen.
9.2.2 Boxplots und Errorbars
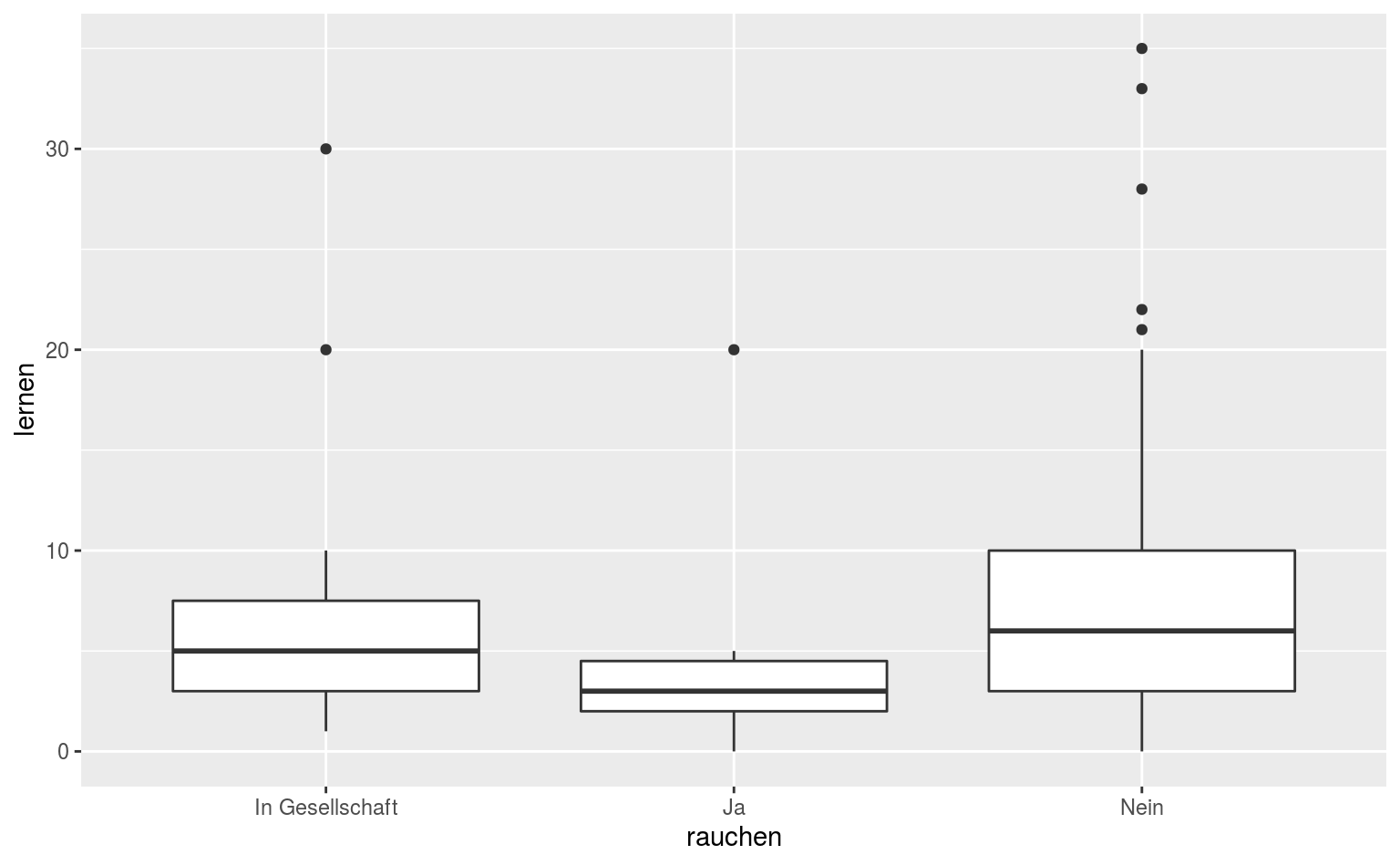
Wenn ihr woanders die base Funktion boxplot (ugh) gesehen habt, dann habt ihr vermutlich auch univariate Boxplots gesehen, sprich keine Gruppierung. Das… kann man machen, ist aber irgendwie witzlos. Wenn ihr das unbedingt mit ggplot2 machen wollt, dann müsst ihr die x-Achse austricksen und sie auf eine Konstante setzen, wie NA:
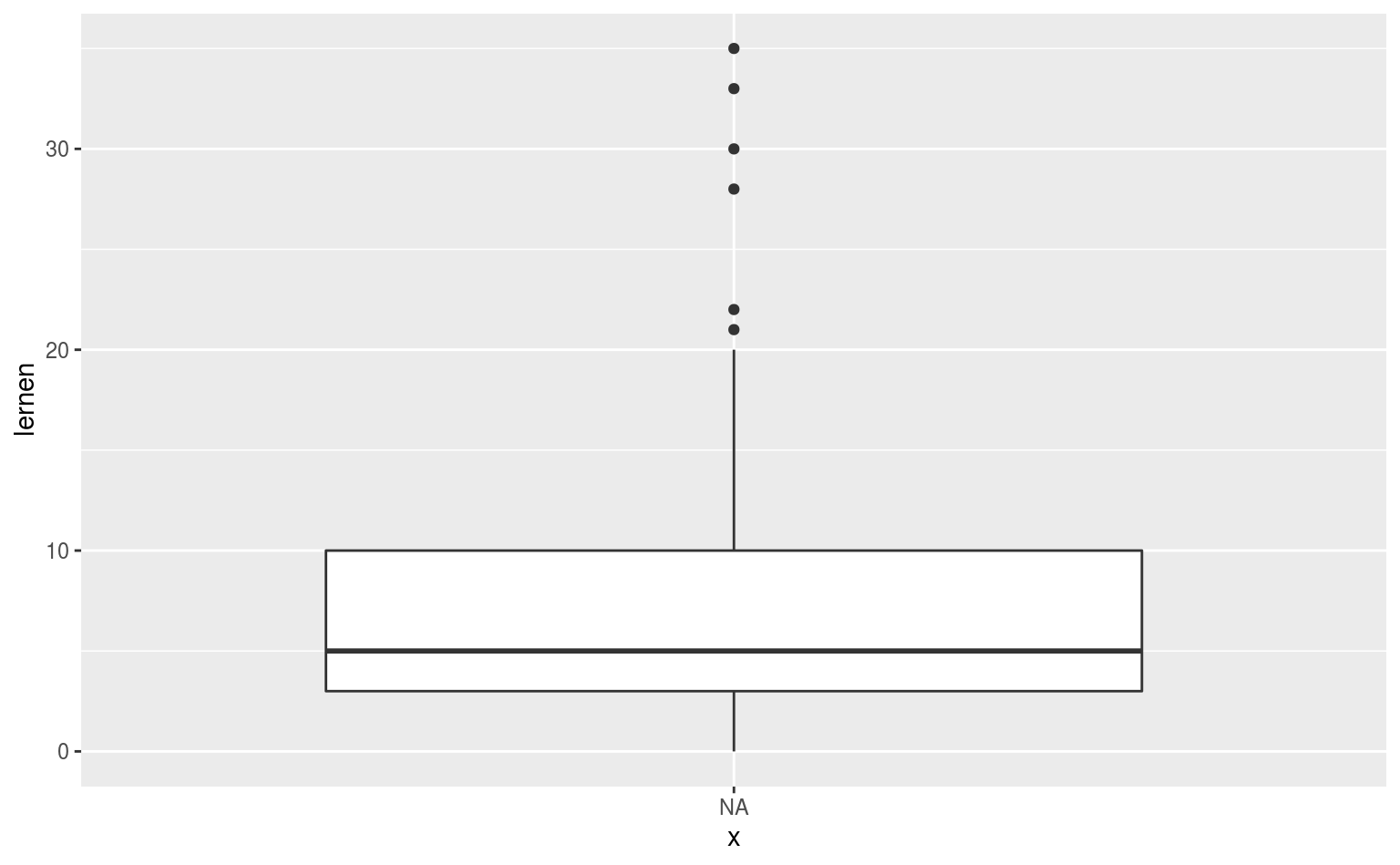
Wenn wir das dann noch in etwas schöner machen wollen, und zum Beispiel 90° rotiert:
ggplot(data = qmsurvey, aes(x = NA, y = lernen)) +
geom_boxplot(alpha = .5, width = .5) +
coord_flip() +
labs(title = "Lernen") +
theme(axis.ticks.y = element_blank(),
axis.title.y = element_blank(),
axis.text.y = element_blank())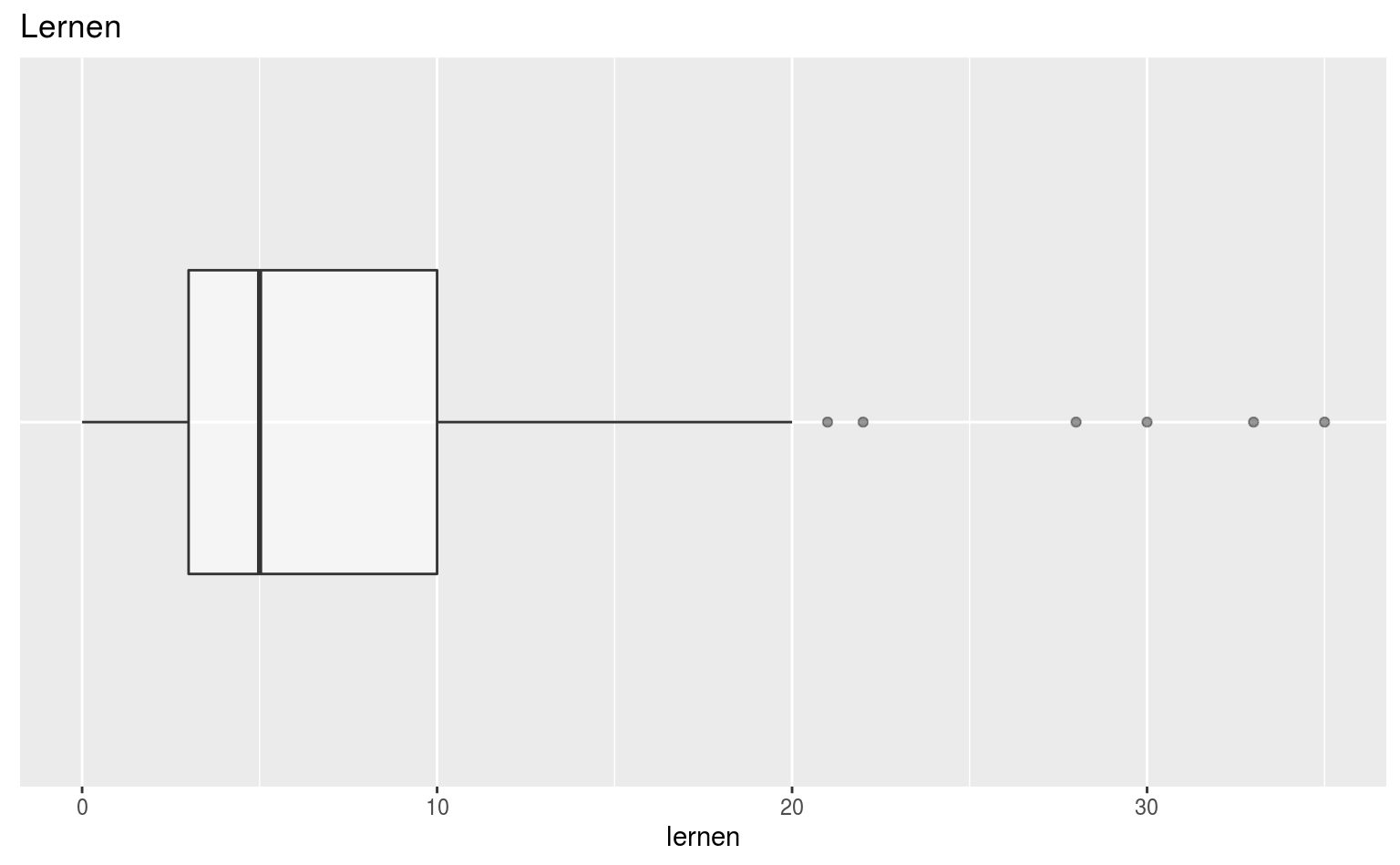
Der Teil im theme ist dazu da, die Labels auf der y-Achse zu verstecken, damit wir das NA aus unserem kleinen Trick da rauskriegen.
Ansonsten ist das Ding immer noch ziemlich langweilig, aber naja.
Meine derzeit präferierte Art Boxplots zu bauen ist ein Boxplot mit Punkten im Hintergrund, um die Menge und grobe Verteilung der Werte besser zu veranschaulichen:
ggplot(data = qmsurvey, aes(x = rauchen, y = lernen, color = rauchen)) +
geom_point(position = "jitter") +
geom_boxplot(alpha = .25, outlier.alpha = 0) +
scale_color_brewer(palette = "Dark2", guide = FALSE)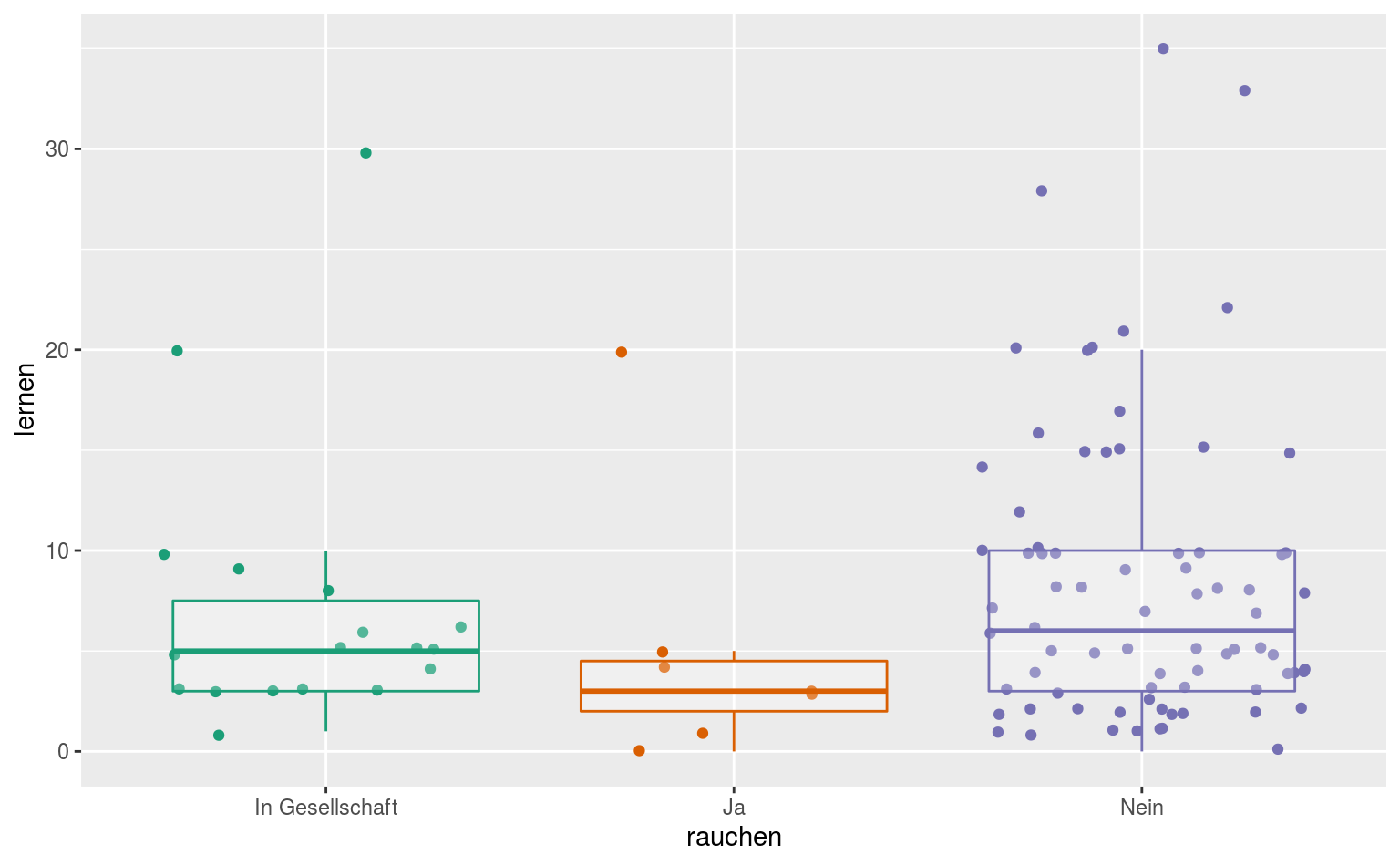
Hier setzen wir noch das alpha für die Ausreißer im Boxplot auf 0, weil wir ja durch das geom_point sowieso alle Punkte geplottet haben.
“Und was ist mit den Whiskern?” höre ich spitzfindige Lesende im Kanon kreischen.
Öhm, naja, Whisker können wir über Error Bars simulieren, in etwa so:
ggplot(data = qmsurvey, aes(x = rauchen, y = lernen, color = rauchen)) +
stat_boxplot(geom = "errorbar", width = .5) +
geom_boxplot() +
scale_color_brewer(palette = "Dark2", guide = FALSE)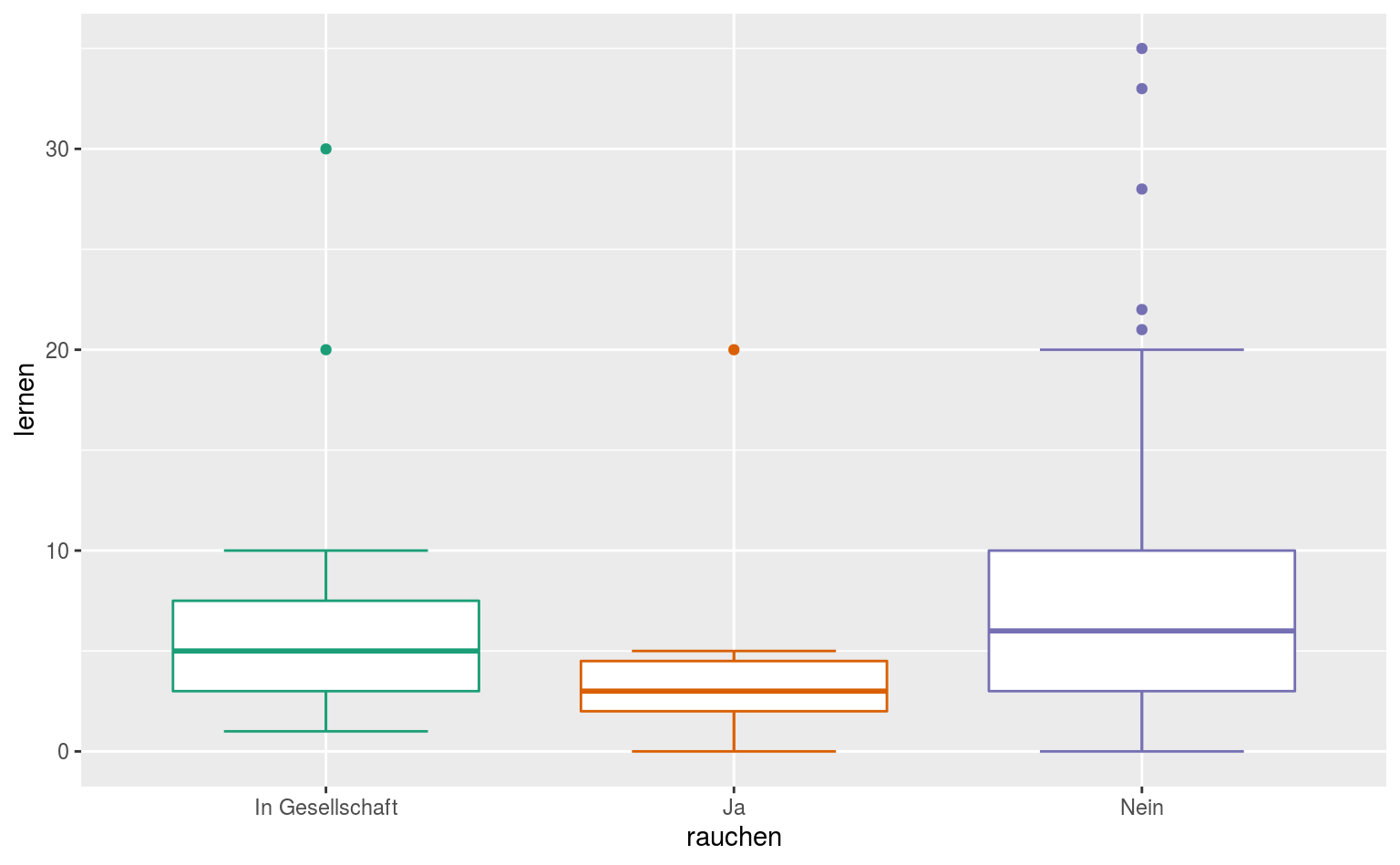
Error Bars sind auch so ganz nützlich, zum Beispiel für Konfidenzintervalle. Wir müssen die KIs nichtmal selber berechnen, genauso wie wir für Boxplots keine Quartile berechnen müssen.
ggplot(data = qmsurvey, aes(x = rauchen, y = lernen, color = rauchen)) +
stat_summary(fun.data = mean_cl_normal, geom = "errorbar") +
scale_color_brewer(palette = "Dark2", guide = FALSE)#> Warning: Computation failed in `stat_summary()`:
#> Hmisc package required for this function
Hier haben wir 95% Konfidenzintervalle um den Mittelwert. Wir ihr seht, reicht nicht einfach ein geom_errorbar, weil Error Bars zu allgemein sind und nicht immer automatisch mit den selben Werten angewendet werden, wie wir es bei Boxplots gewohnt sind.
Wir können hier auch zusätzlich noch die Mittelwerte einzeichnen:
ggplot(data = qmsurvey, aes(x = rauchen, y = lernen, color = rauchen)) +
stat_summary(fun.data = mean_cl_normal, geom = "errorbar", position = "dodge") +
stat_summary(fun.y = mean, geom = "point", size = 3) +
scale_color_brewer(palette = "Dark2", guide = FALSE)#> Warning: Computation failed in `stat_summary()`:
#> Hmisc package required for this function
9.2.3 Scatterplots und Regressionsgerade
Scatterplots sind, grob gesagt, das mit den Punkten. Am besten geeignet sind sie für bivariate Visualisierung zweier numerischer Variablen, wie etwa die Zufriedenheit im Studium abhängig vom Alter:
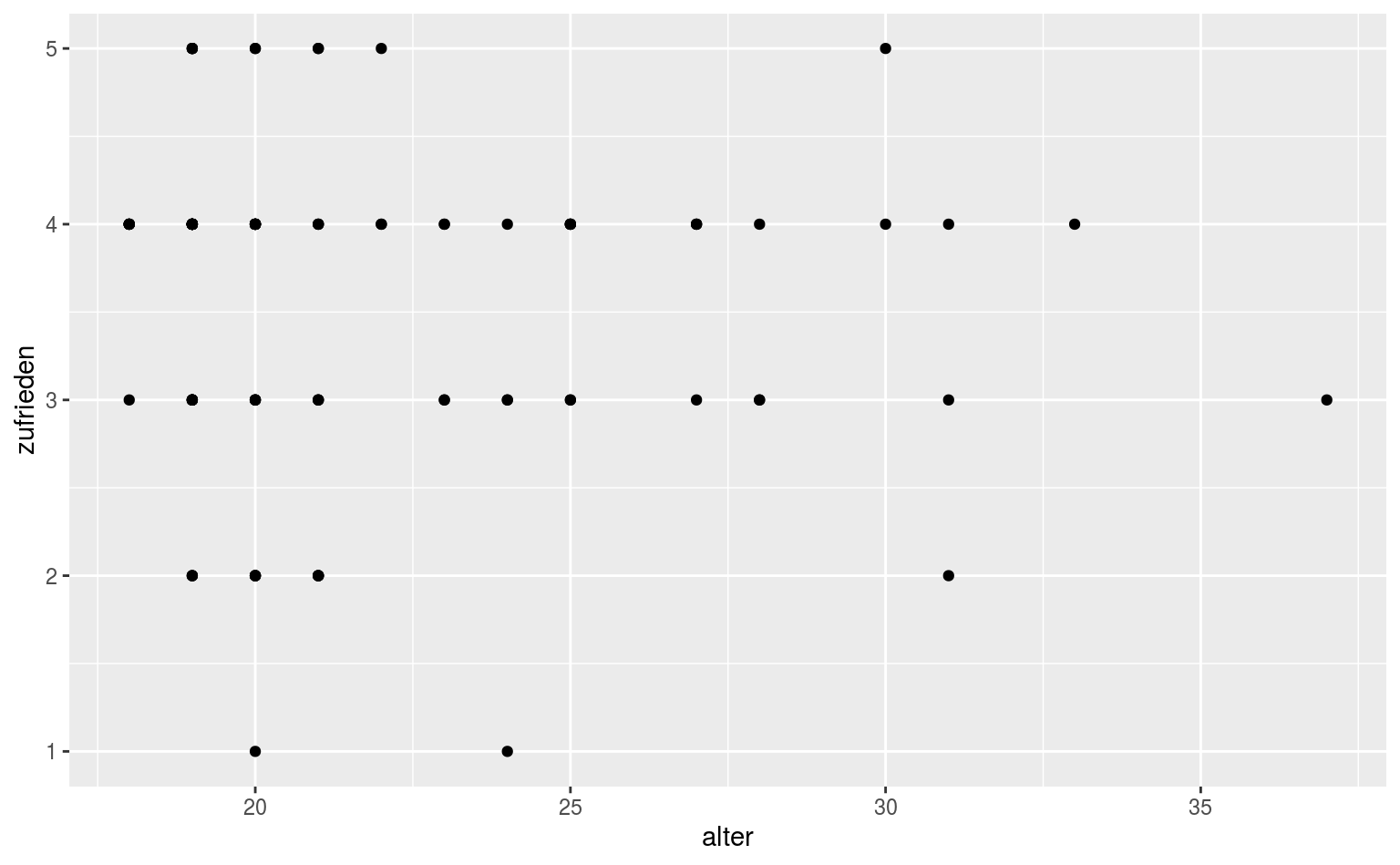
Das Problem an dieser Stelle ist, dass wir sehr viele Punkte haben, die sich überlagern, und wir daher nicht einschätzen können, wie die verteilung tatsächlich aussieht. Eine einfache Möglichkeit ist hier jittering, wir lassen also alle Punkte ein bisschen “jittern”:
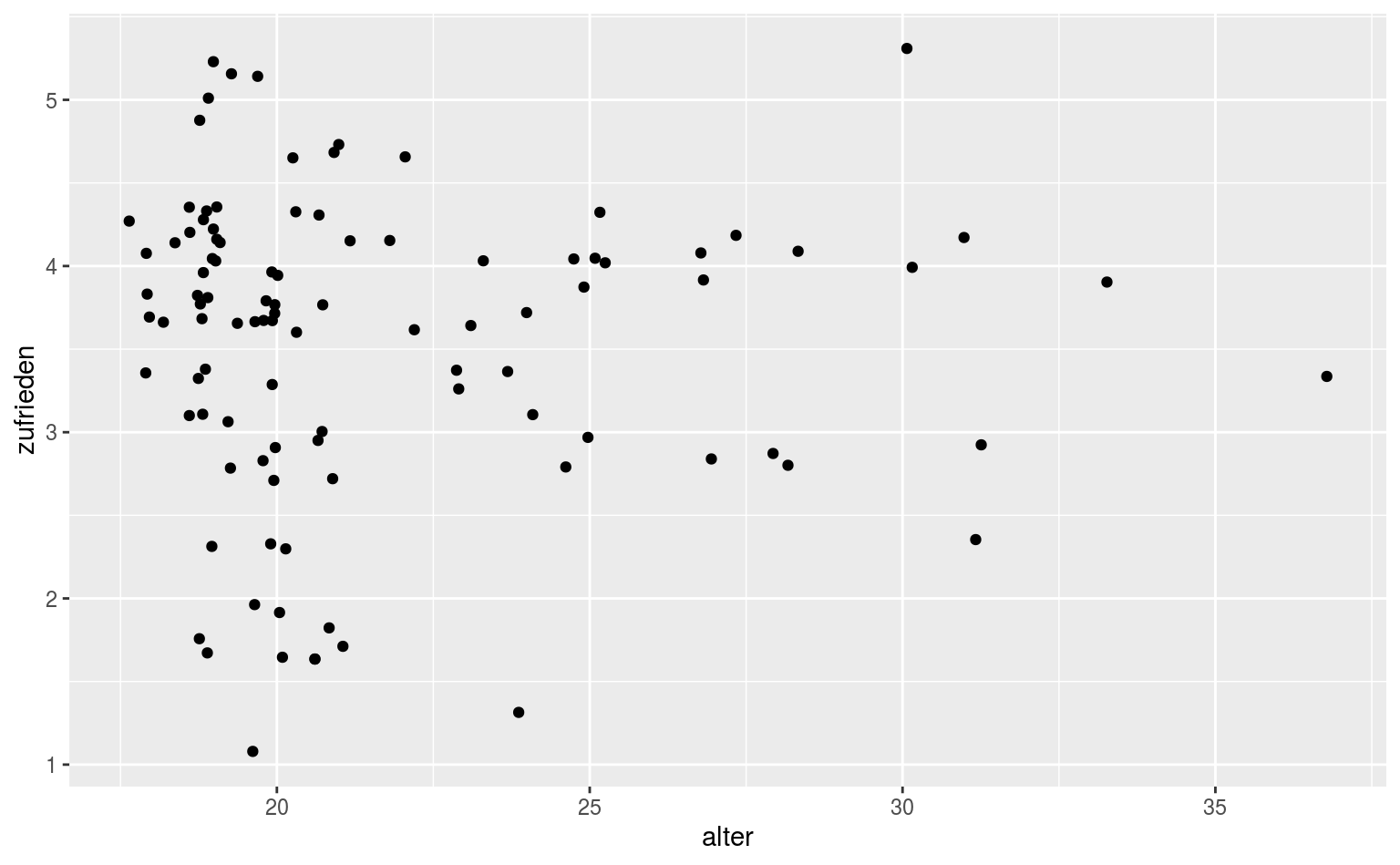
Das Problem hierbei ist, dass wir die Punkte ja minimal verfälschen. Für etwas mehr Kontrolle können wir auch direkt geom_jitter benutzen, das uns etwas mehr Kontrolle gibt:
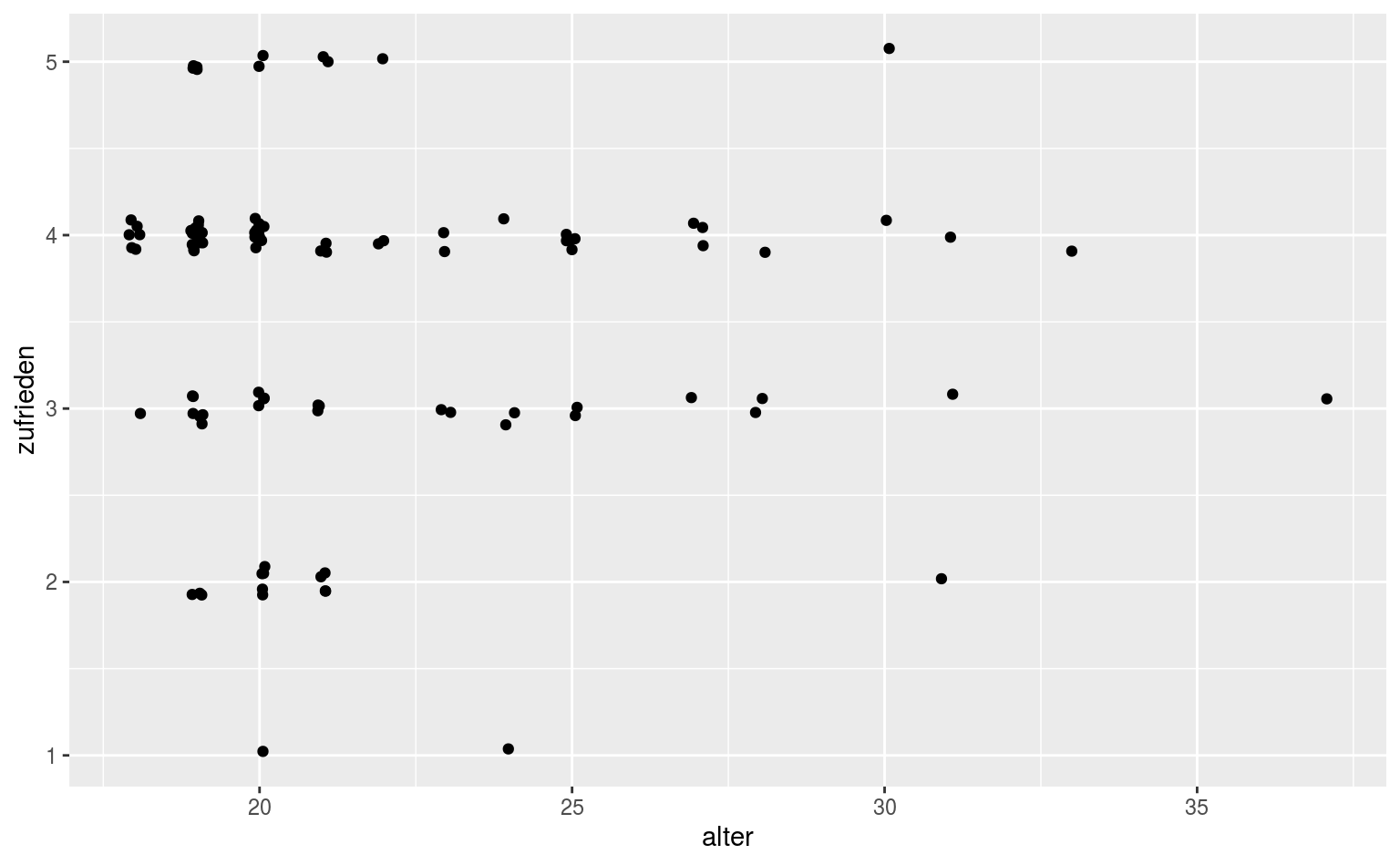
Hier sagen wir den Punkten, dass sie maximal 10% horizontal oder vertikal jittern sollen, was unsere Daten weniger verzerrt, aber uns immernoch einen etwas besseren Einblick erlaubt.
Wir können auch die Punktgröße abhängig von der Anzahl der Datenpunkte an jeder Stelle machen, dafür brauchen wir allerdings etwas data munging im Vorfeld.
qmsurvey %>%
count(alter, zufrieden) %>%
ggplot(aes(x = alter, y = zufrieden, size = n)) +
geom_point()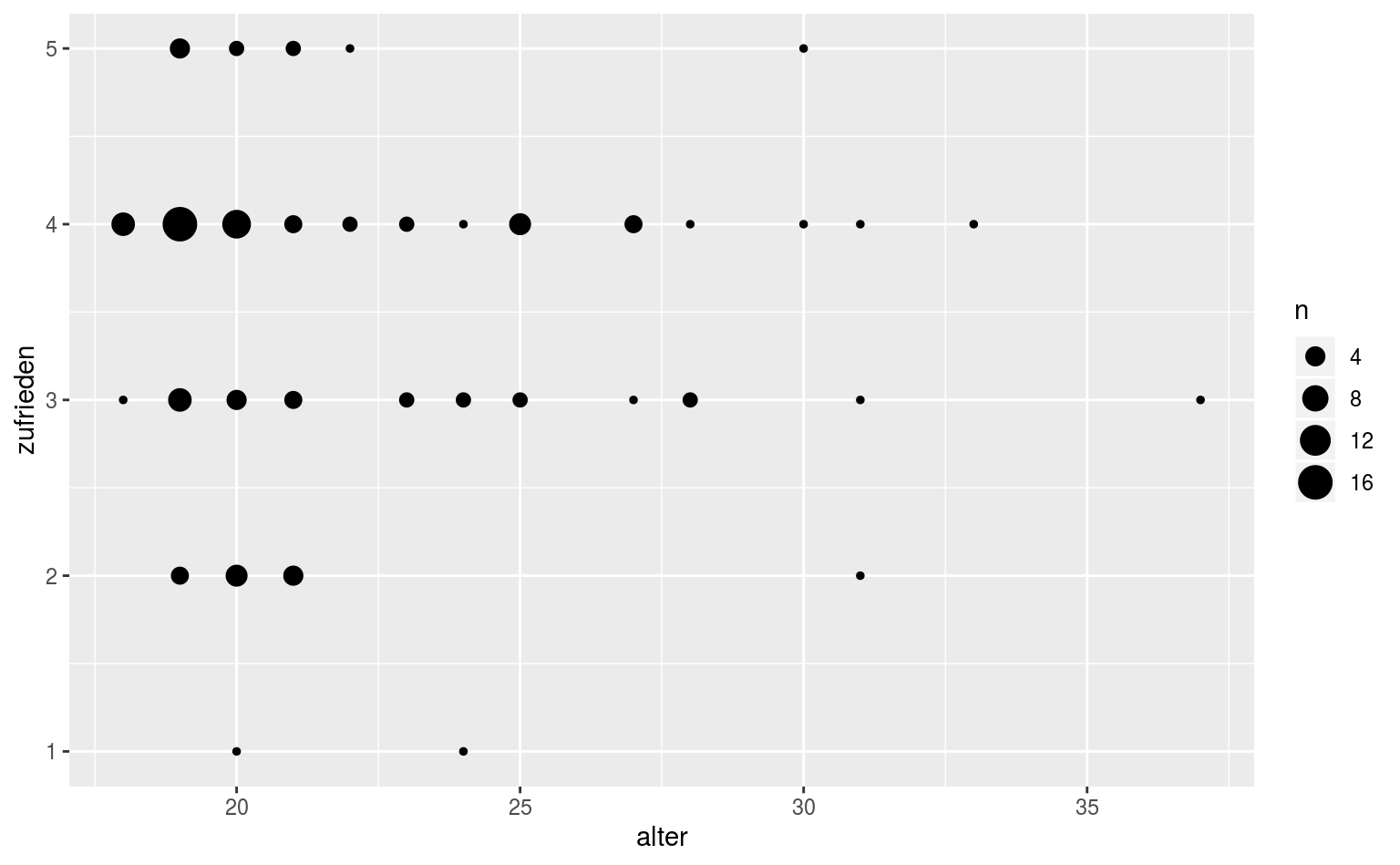
Mit count haben wir hier jede Kombination aus alter und zufrieden durchgezählt und eine Variable n erhalten, und von dieser machen wir so die Punktgröße abhängig. Größerer Punkt, mehr Datenpunkte an dieser Stelle. Einfach. Gut sichtbar.
Als nächstes können wir lineare Zusammenhänge veranschaunlichen, indem wir Regressionsgeraden durch unsere Punkte ziehen. Als Beispiel anhand der Variablen arbeit und lernen:
ggplot(data = qmsurvey, aes(x = lernen, y = arbeit)) +
geom_point() +
geom_smooth(method = lm, se = FALSE)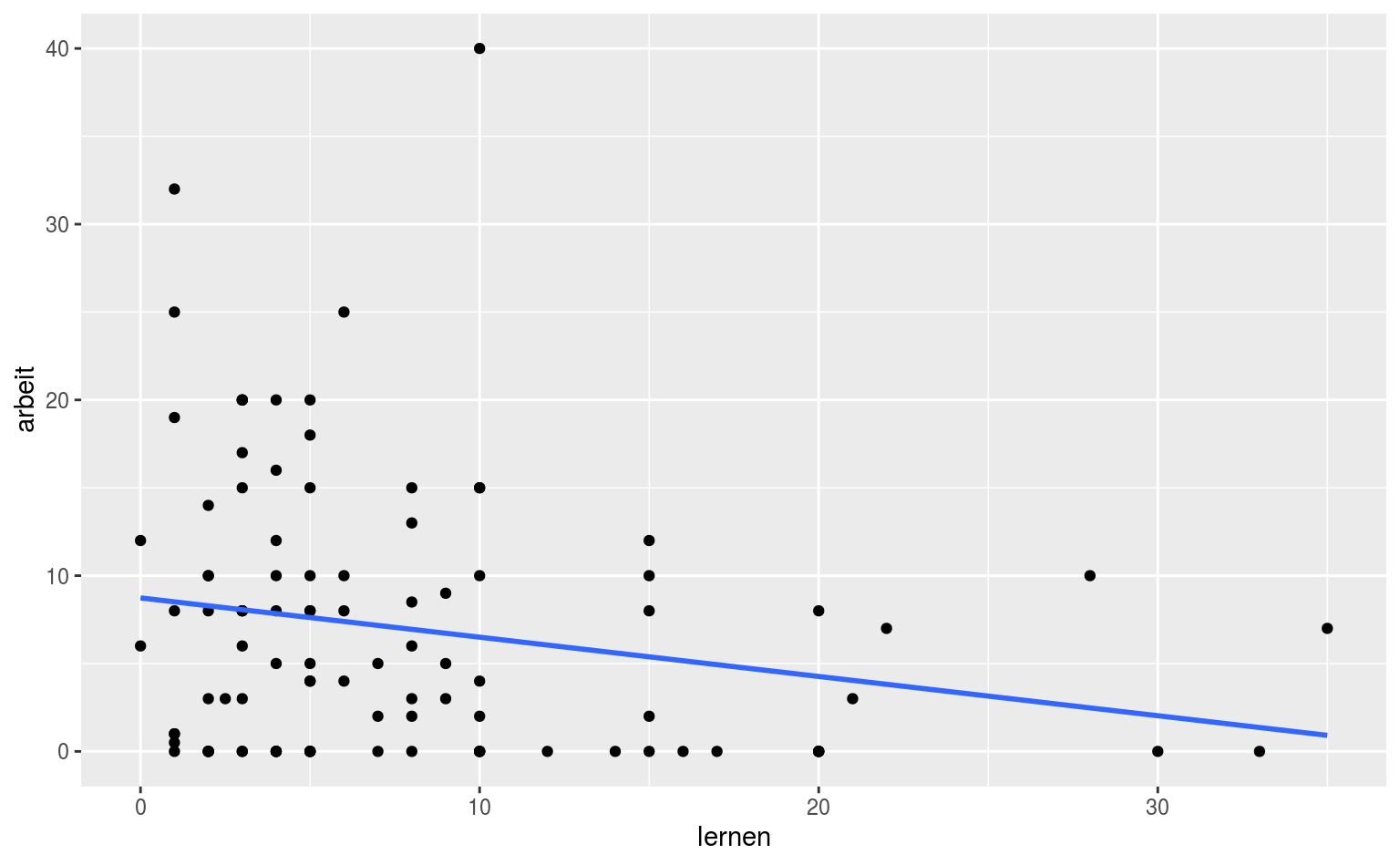
Sieh an, wer mehr lernt, hat weniger Zeit zum arbeiten. So grob.
geom_smooth kann beliebige Arten von Schätzlinien durch eure Daten ziehen, in diesem Fall sagen wir mit method = lm, dass es eine Regressionsgerade aus einem Linearen Modell werden soll, mittels der gleichnamigen Funktion lm. Zusätzlich sagen wir mit se = FALSE, dass wir kein Konfidenzband wollen.
Wenn ihr geom_smooth ohne Zusatzargumente benutzt, bekommen ihr ein loess-Smoothing mit Konfidenzband. Loess ist ziemlich schnieke von dem was es tut, aber in der Regel nicht inhaltlich relevant für unsere relativ simplen Anwendungsfälle:
#> `geom_smooth()` using method = 'loess' and formula 'y ~ x'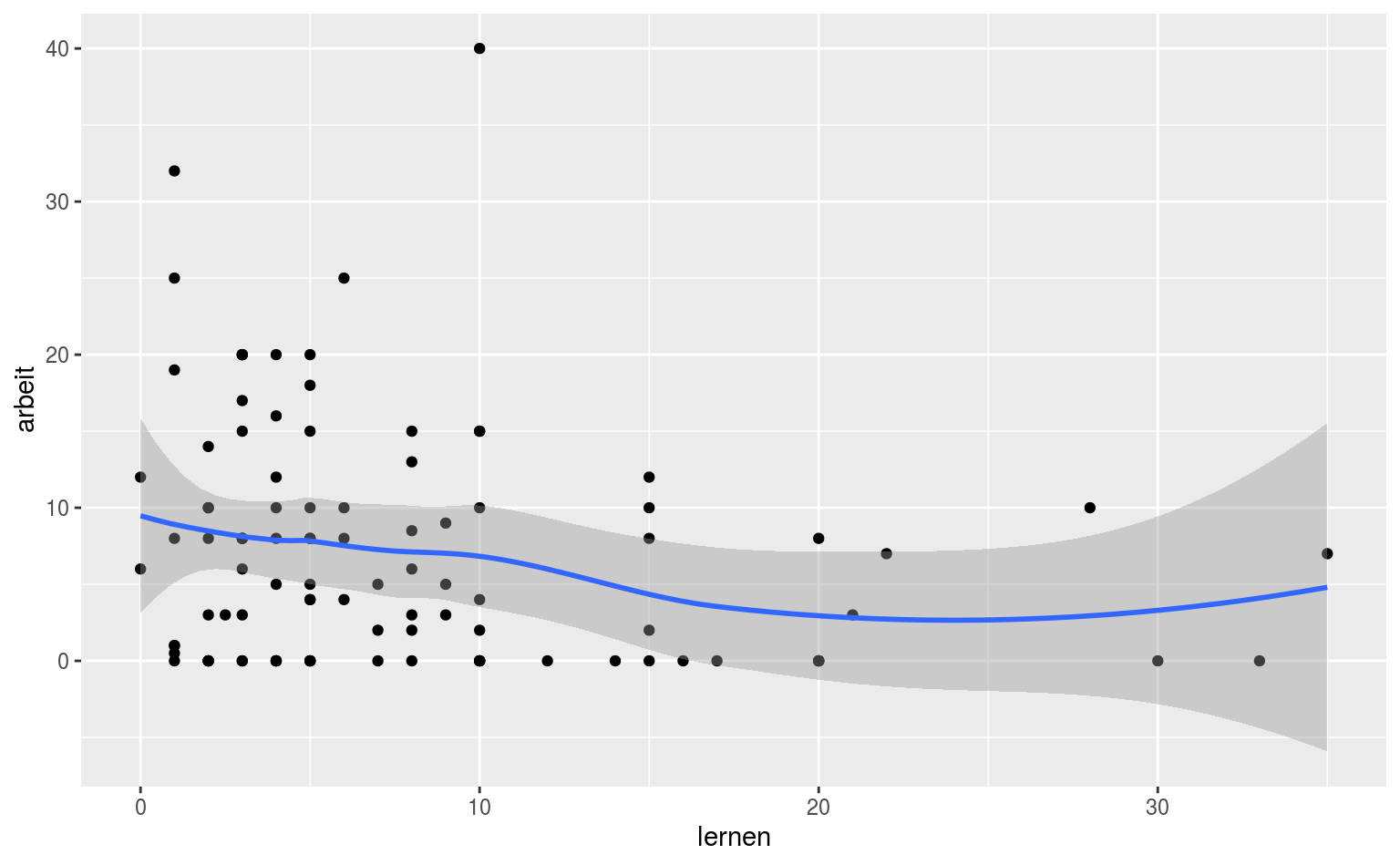
Spooky. Lokale polynomiale Regression und so. Wenn euch langweilig ist, lest die Hilfe in ?loess, ansonsten sei nur gesagt, dass wir das im Kontext linearer Regression nicht benutzen.
Achja, wir können natürlich auch unsere Punkte beliebig einfärben, zum Beispiel nach einer Drittvariable:
ggplot(data = qmsurvey, aes(x = lernen, y = arbeit, color = gender)) +
geom_point() +
scale_color_brewer(palette = "Set1")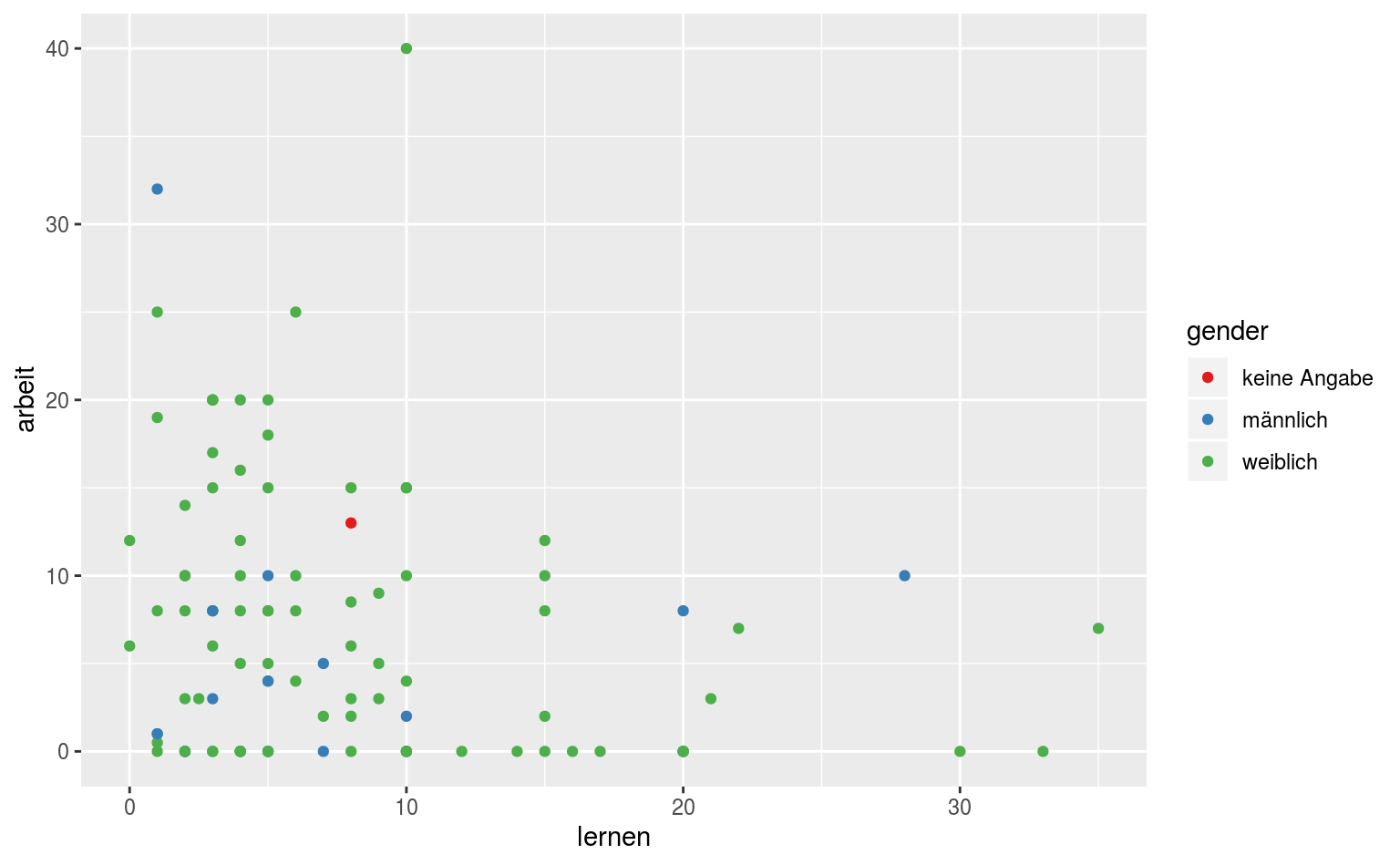
ggplot(data = qmsurvey, aes(x = lernen, y = arbeit, color = gender)) +
geom_point() +
geom_smooth(method = lm, se = FALSE) +
scale_color_brewer(palette = "Set1")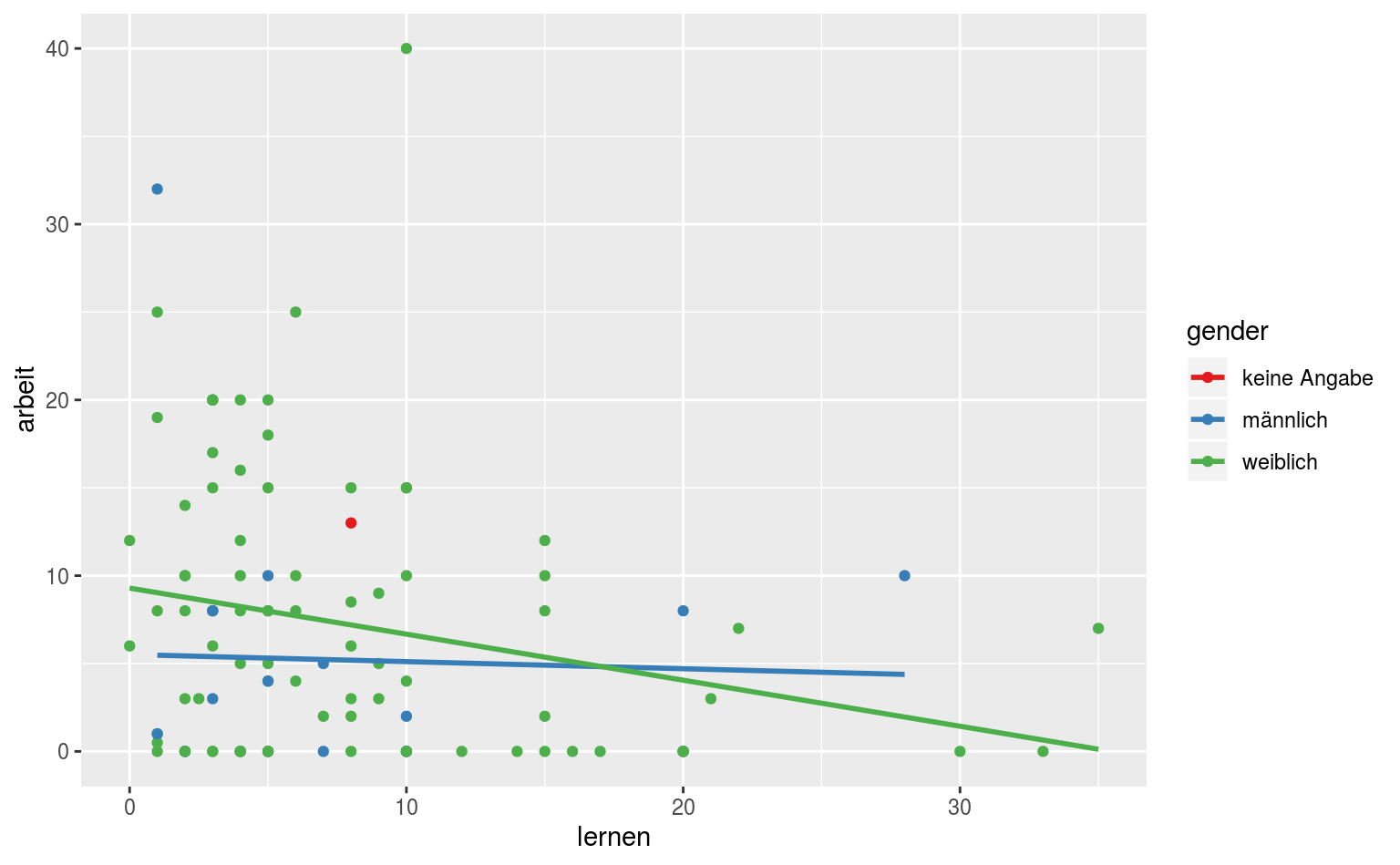
Zu Farbpaletten kommen wir weiter unten nochmal, aber hier sehen wir schonmal ein einfaches Beispiel für einen Scatterplot zweier Variablen mit Farbkodierung nach einer Drittvariable.
Mehr als 3 Variablen auf einem Scatterplot zu verbauen würde ich auch nicht empfehlen, auch wenn es theoretisch möglich wäre.
Ein Maximalbeispiel sensorischer Überforderung:
ggplot(data = qmsurvey, aes(x = lernen, y = arbeit,
color = gender, fill = rauchen,
alpha = zufrieden, size = alter)) +
geom_point(shape = 21, stroke = 2) +
scale_color_brewer(palette = "Set1") +
scale_fill_brewer(palette = "Dark2") +
theme(legend.position = "bottom",
legend.box = "vertical")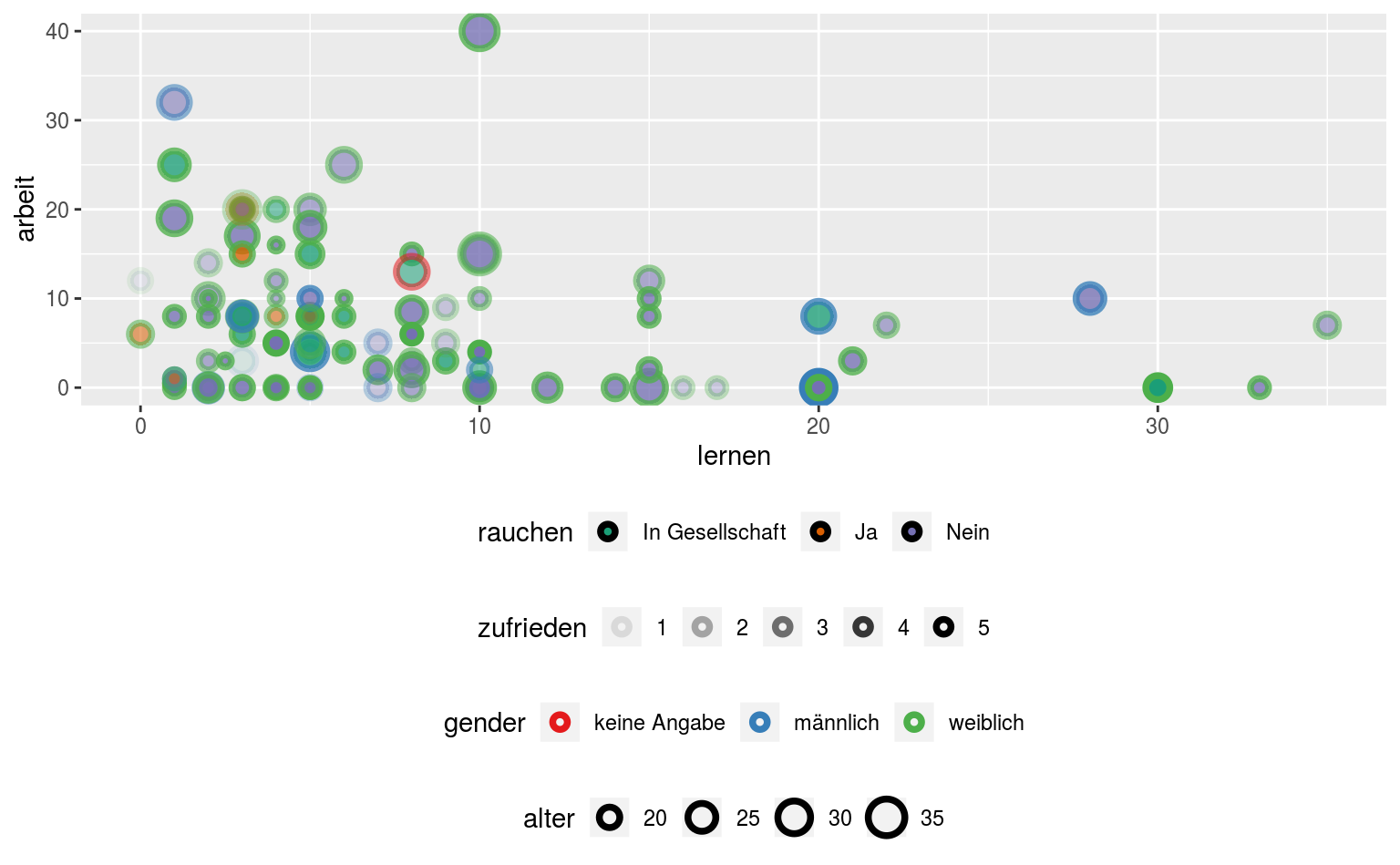
Das ist albern. Was wir hier haben:
color: Umrandungsfarbe abhängig vongenderfill: Füllfarbe abhängig vonrauchenalpha: Transparenz abhängig vonzufriedensize: Größe abhängig vonalter
Sowas einfach nicht machen.
9.2.4 Facetting
9.2.5 Spaßiger Kram
library(dplyr)
library(ggplot2)
seq(from = -10, to = 10, by = 0.05) %>%
expand.grid(x = ., y = .) %>%
ggplot(aes(x = (x + pi * sin(y)), y = (y + pi * sin(x)))) +
geom_point(alpha = .1, shape = 20, size = 1, color = "black") +
coord_equal() +
theme_void()
Das fällt unter den Punkt “generative art”, und ist durchaus schön, aber geht auch ein bisschen auf die CPU.
9.3 Mach mal bunt!
Okay, wir wollen also die Balken bunt machen. Es gibt zwei Möglichkeiten: Die color und fill. Ersteres ist die Farbe (duh), zweiteres die Füllfarbe (duhuh), und unterschiedliche geoms haben da entsprechende Unterschiede.
ggplot(data = gotdeaths, aes(x = death_season)) +
geom_bar(color = "red") +
labs(title = "Game of Thrones: Deaths",
subtitle = "Deaths per Season",
x = "Season", y = "# of Deaths")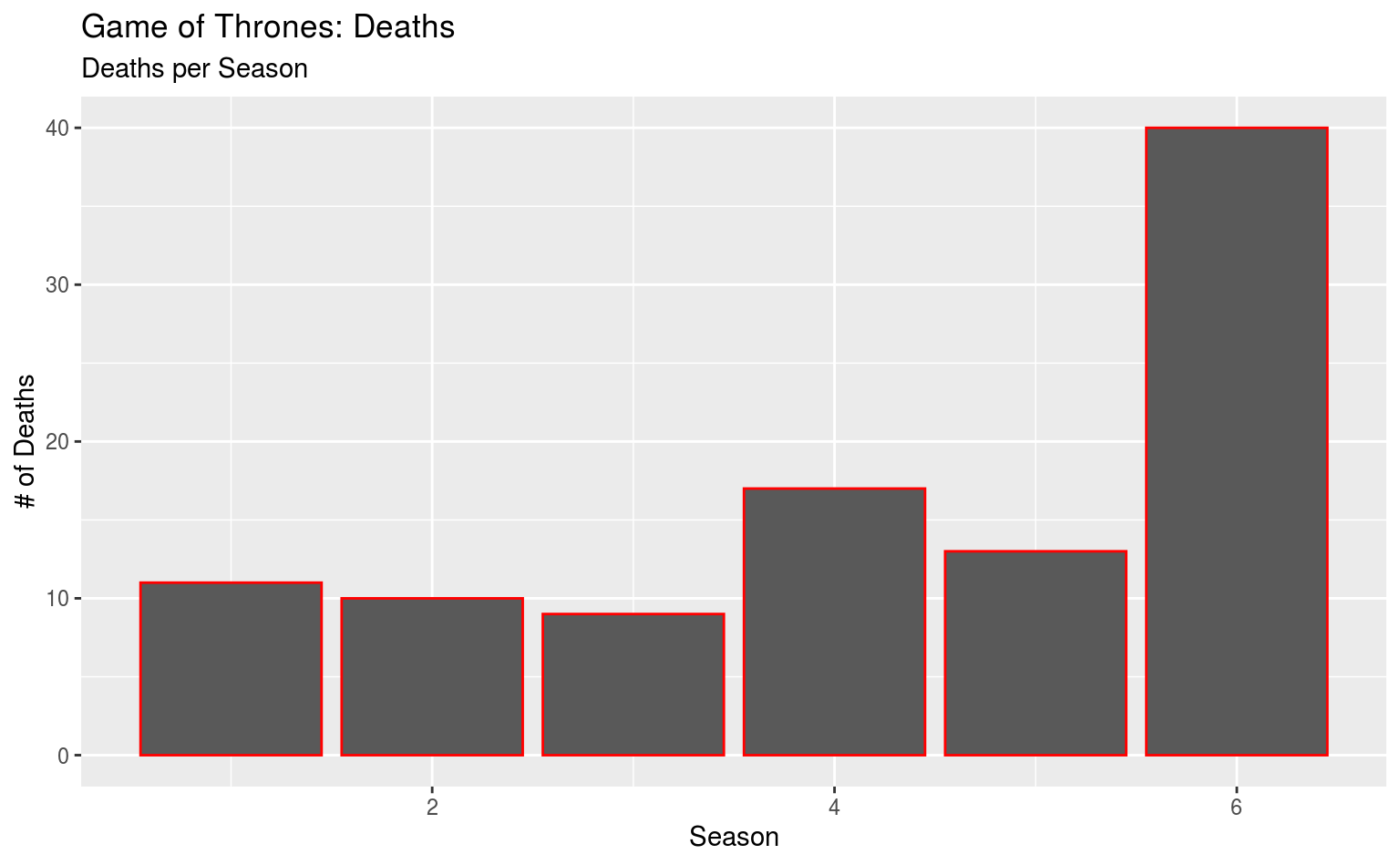
Jetzt haben wir rote Umrandungen. Nicht sehr beeindruckend.
ggplot(data = gotdeaths, aes(x = death_season)) +
geom_bar(fill = "red") +
labs(title = "Game of Thrones: Deaths",
subtitle = "Deaths per Season",
x = "Season", y = "# of Deaths")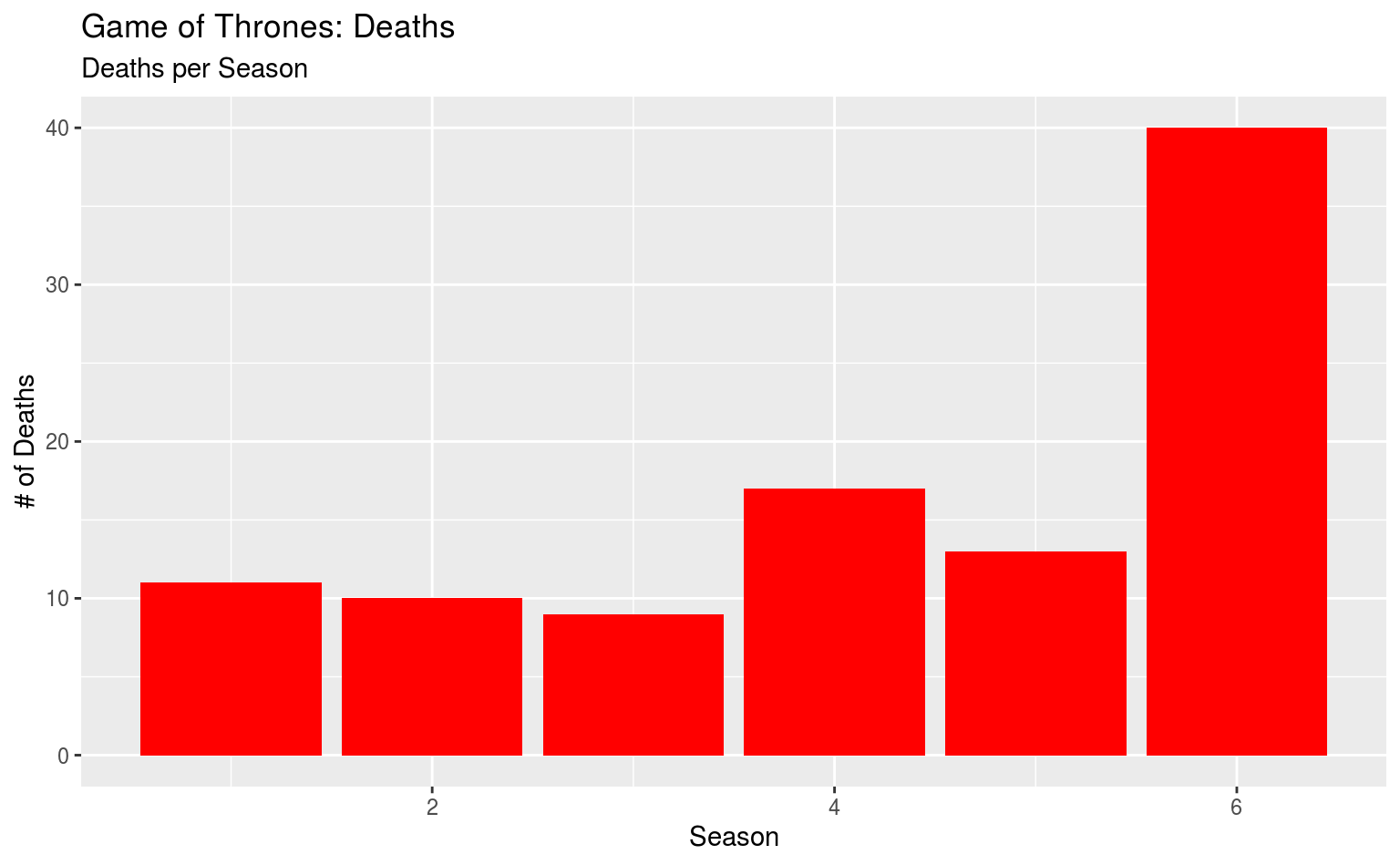
Ein bisschen grell, aber immerhin rot.
ggplot(data = gotdeaths, aes(x = death_season)) +
geom_bar(fill = "darkred", color = "black") +
labs(title = "Game of Thrones: Deaths",
subtitle = "Deaths per Season",
x = "Season", y = "# of Deaths")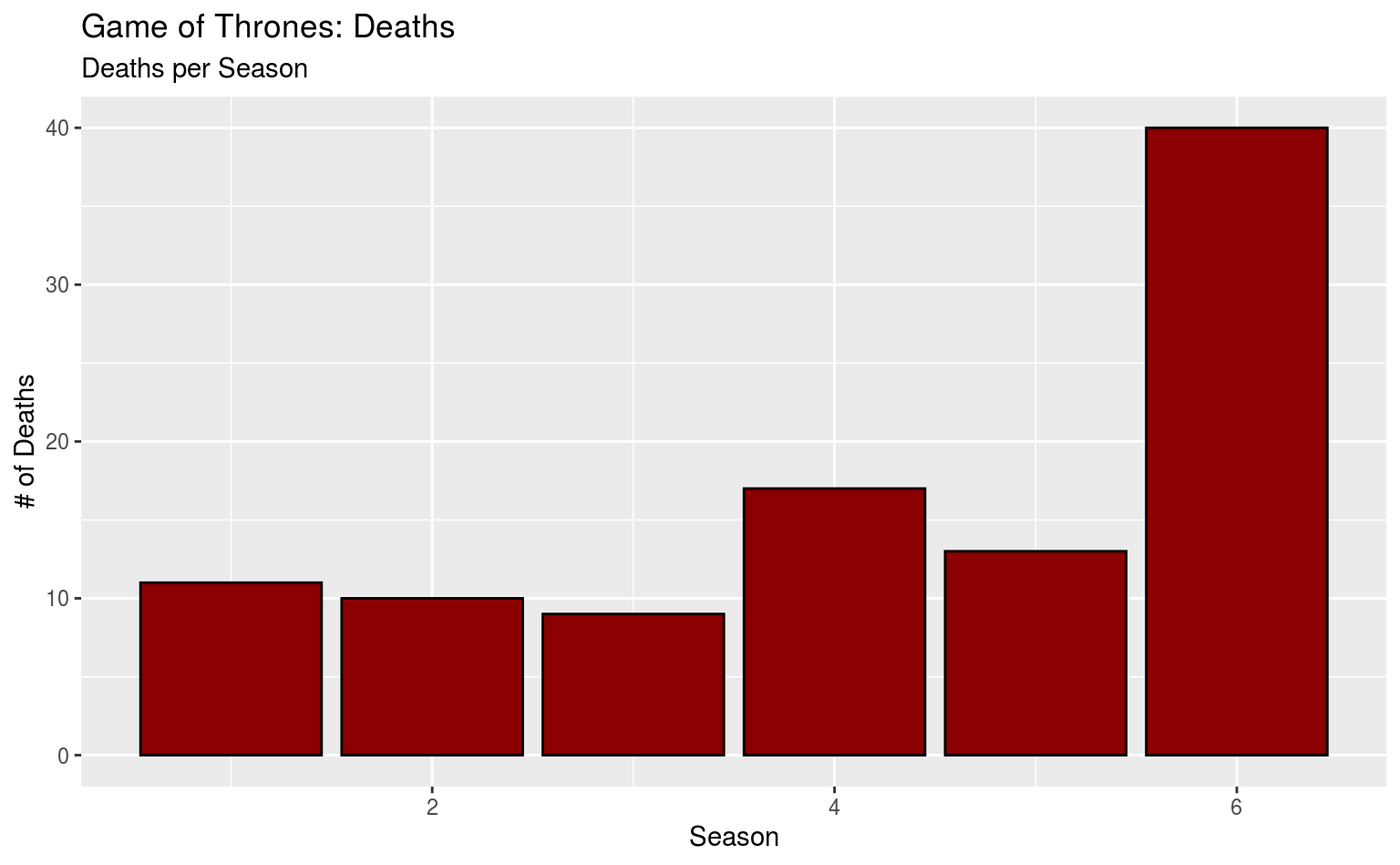
Okay, vielleicht ein bisschen Transparenz noch?
ggplot(data = gotdeaths, aes(x = death_season)) +
geom_bar(fill = "darkred", color = "black", alpha = 0.75) +
labs(title = "Game of Thrones: Deaths",
subtitle = "Deaths per Season",
x = "Season", y = "# of Deaths")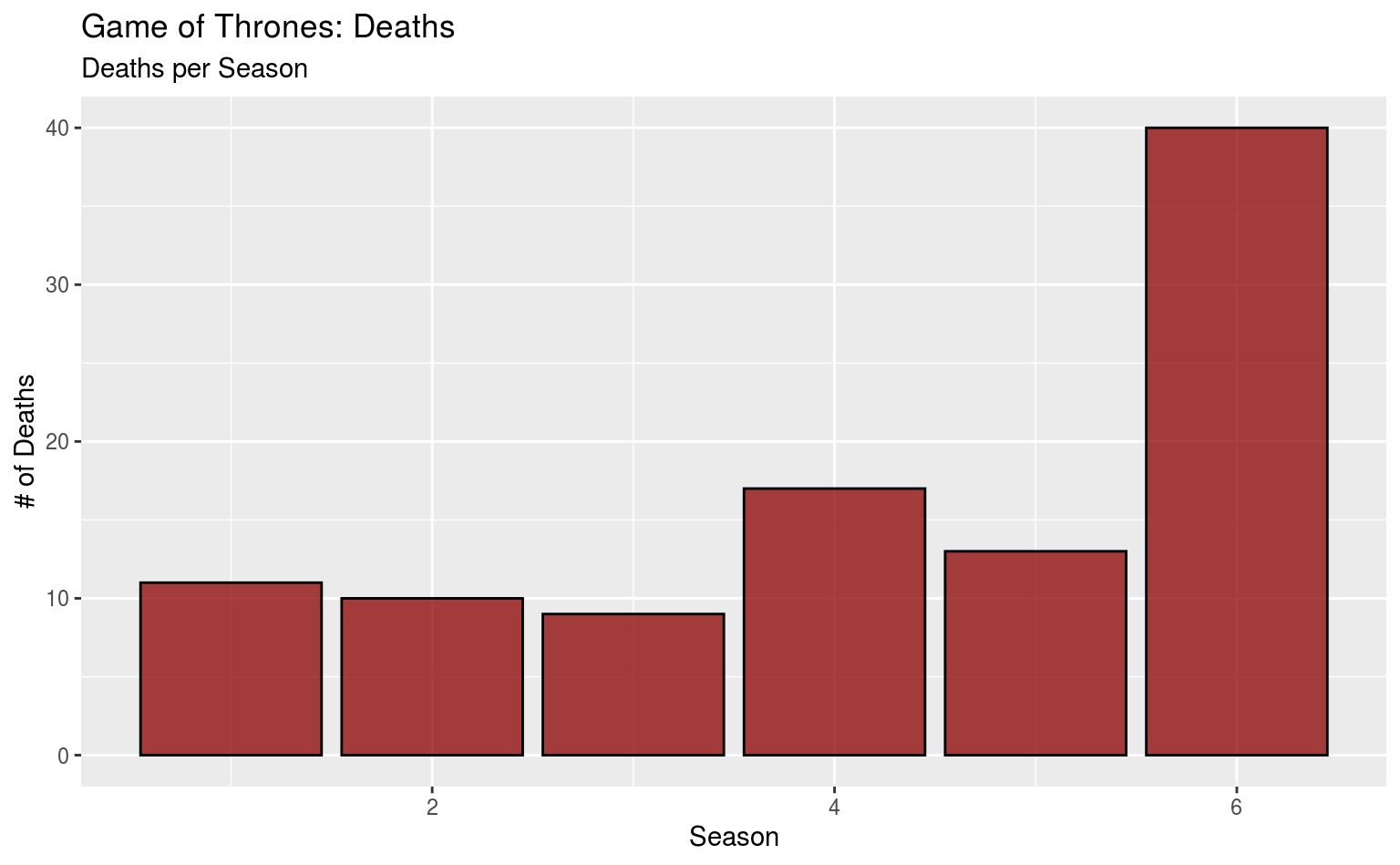
alpha gibt die Durchsichtigkeit des Elements an, von 0 (unsichtbar) bis 1 (keine Transparenz).
Was die Farben angeht: R kennt red und darkred neben etlichen anderen Farben. Diese Farben könnt ihr euch via colors() ausgeben lassen — also zumindest die Namen der Farben.
Alternativ könnt ihr Farben auch als Hex-String angeben, rot wäre dann zum Beispiel #FF0000. Wenn ihr mal “rgb color picker” googlet, findet ihr auch entsprechende tools, oder ihr installiert das colourpicker package und habt dann sowas direkt in RStudio unter “Addins”:
Abbildung 9.1: Colourpicker RStudio Addin
9.3.1 scale_color_* und scale_fill_*
Wenn wir global die Farbe der Balken ändern wollen, können wir das direkt simpel im geom_bar()-Element machen, aber manchmal wollen wir ja auch die Farbe abhängig von einer anderen Variable machen.
Wenn wir einer aesthetic wie fill oder color eine Variable zuordnen wollen, müssen wir das in aes() tun, wo wir auch x und y definieren.
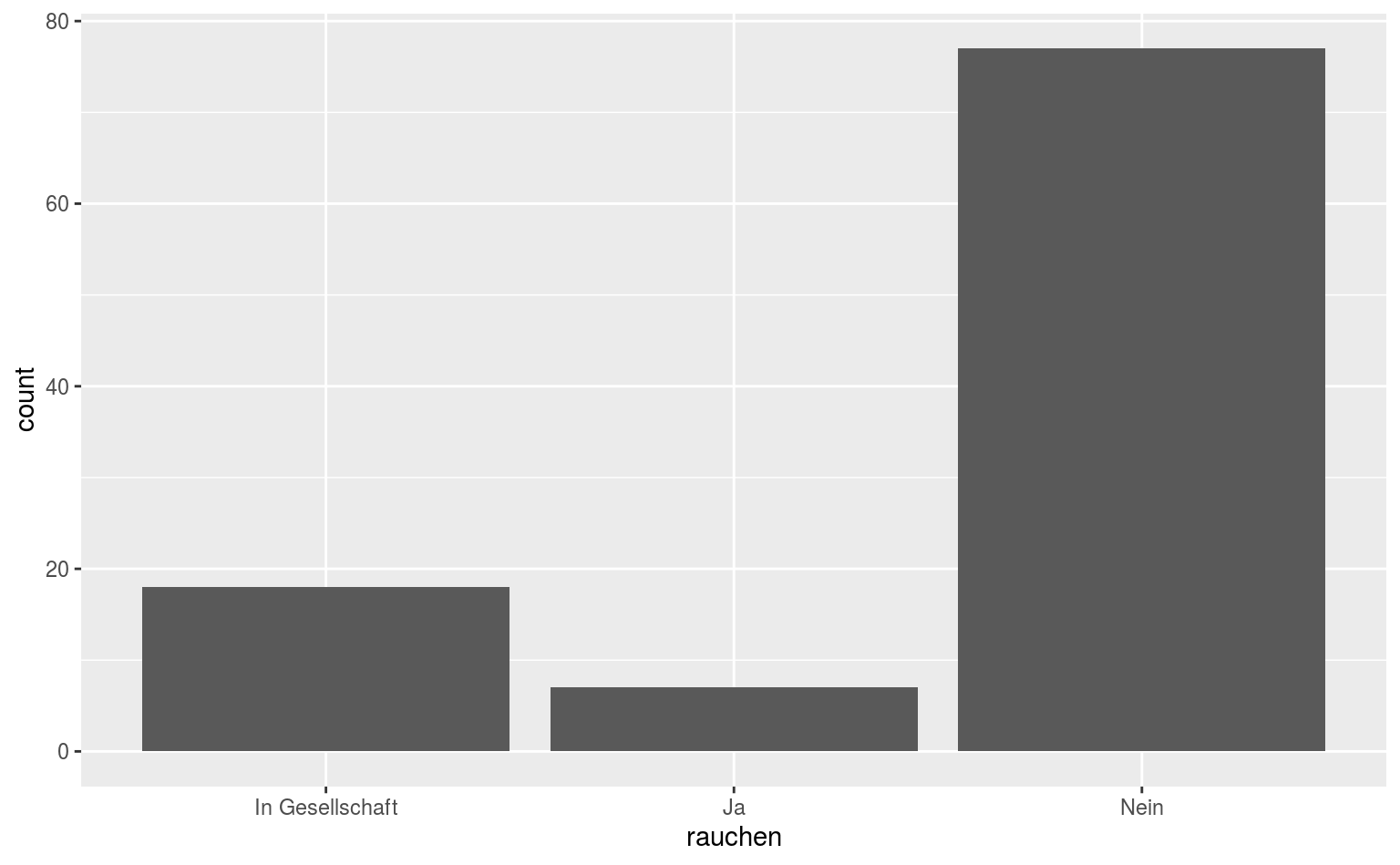
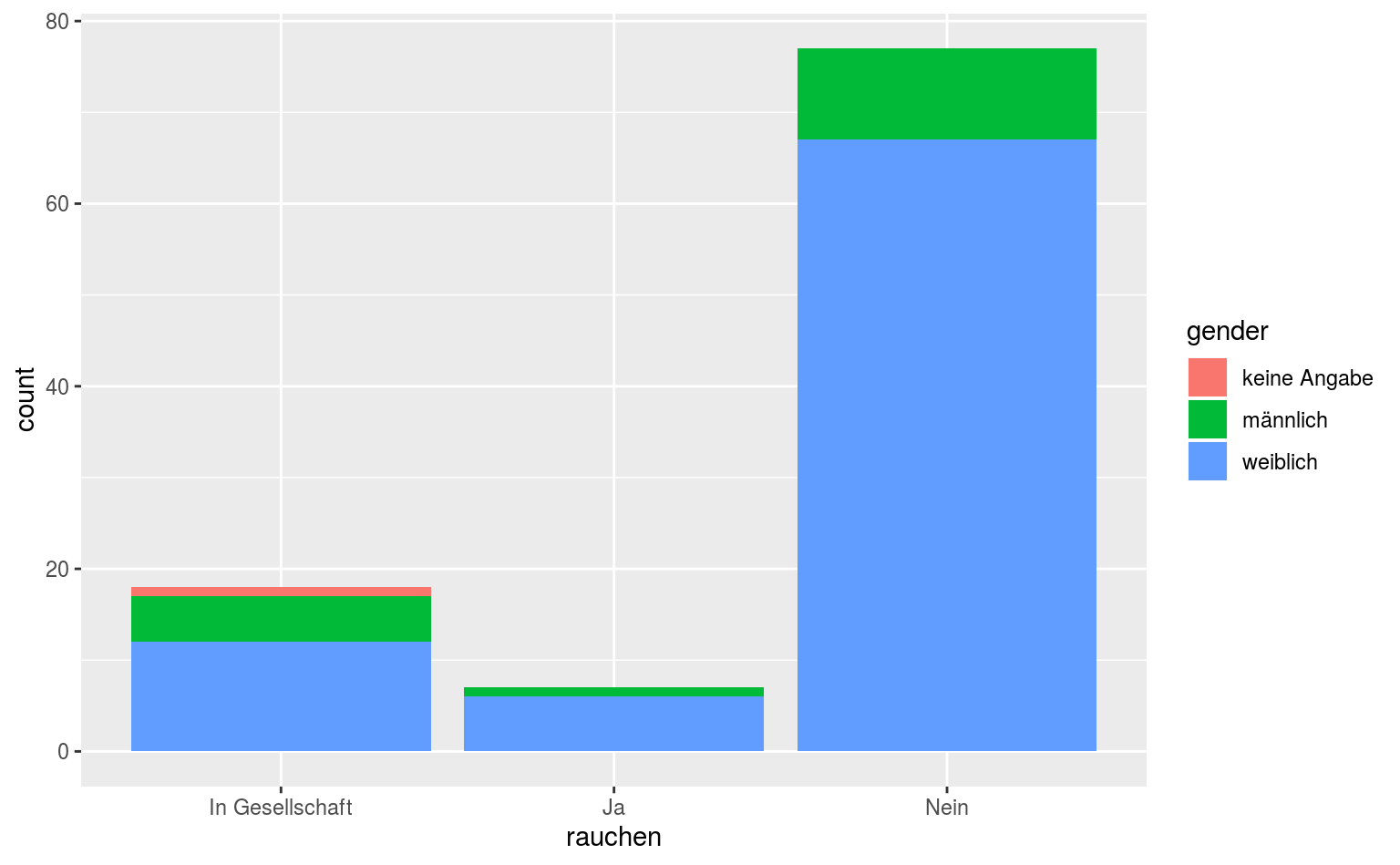
ggplot(data = qmsurvey, aes(x = rauchen, fill = gender)) +
geom_bar(position = "dodge", color = "black", alpha = .75)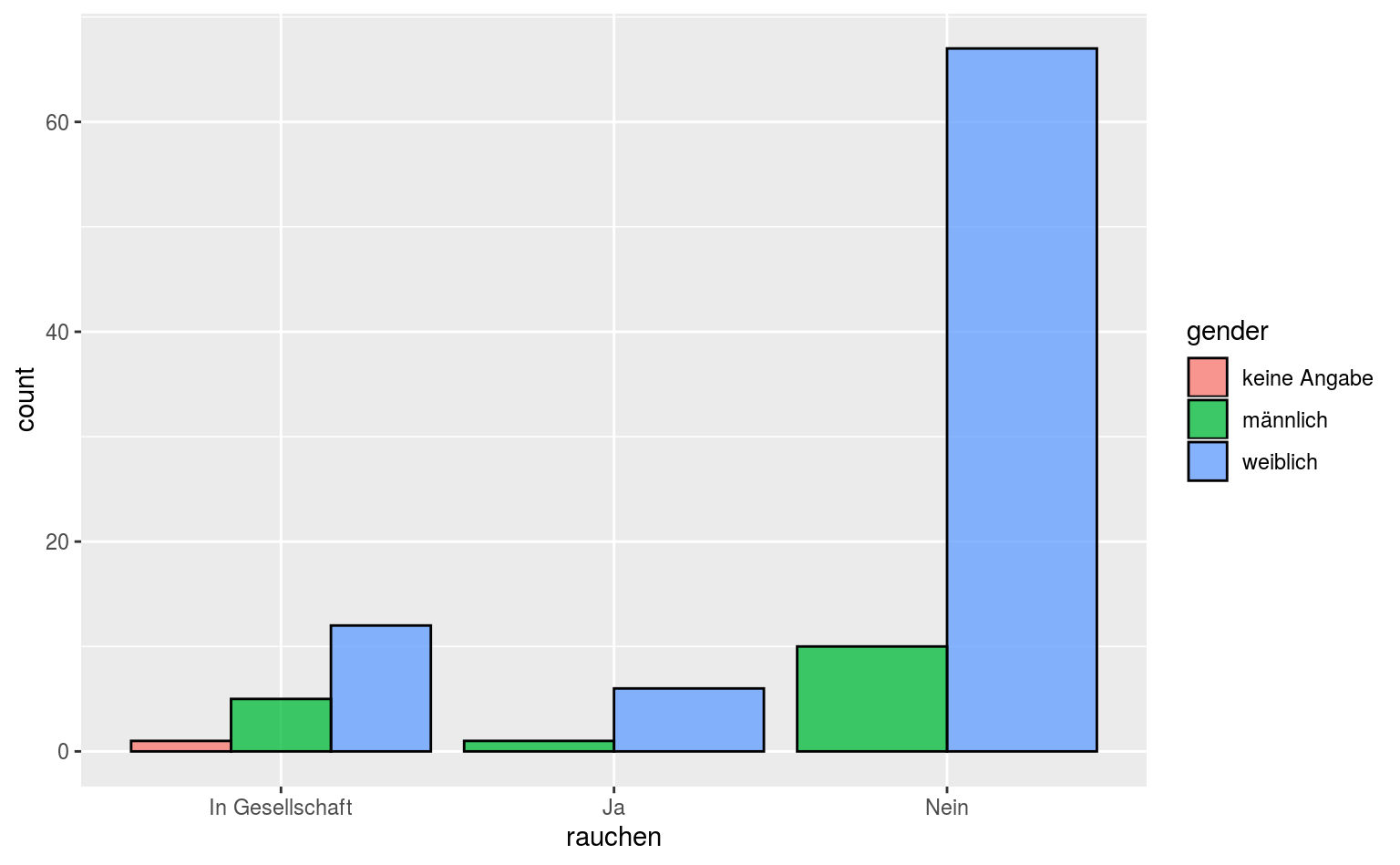
Jetzt haben wir Balken, gefärbt in Abhängigkeit von der Variable gender, in den ggplot2-Standardfarben.
Wenn wir bestimmte Farben für die Zuordnung benutzen wollen, müssen wir die entsprechende scale manuell bearbeiten.
Unter scale fällt in ggplot2 jedes Element eines Plots, das sich einer Variable zuordnen lässt, dazu gehören x und y-Variablen, aber auch die Farbe color und Füllfarbe fill.
Also, ein paar Beispiele:
ggplot(data = qmsurvey, aes(x = rauchen, fill = gender)) +
geom_bar() +
scale_fill_manual(values = c("red", "blue", "green"))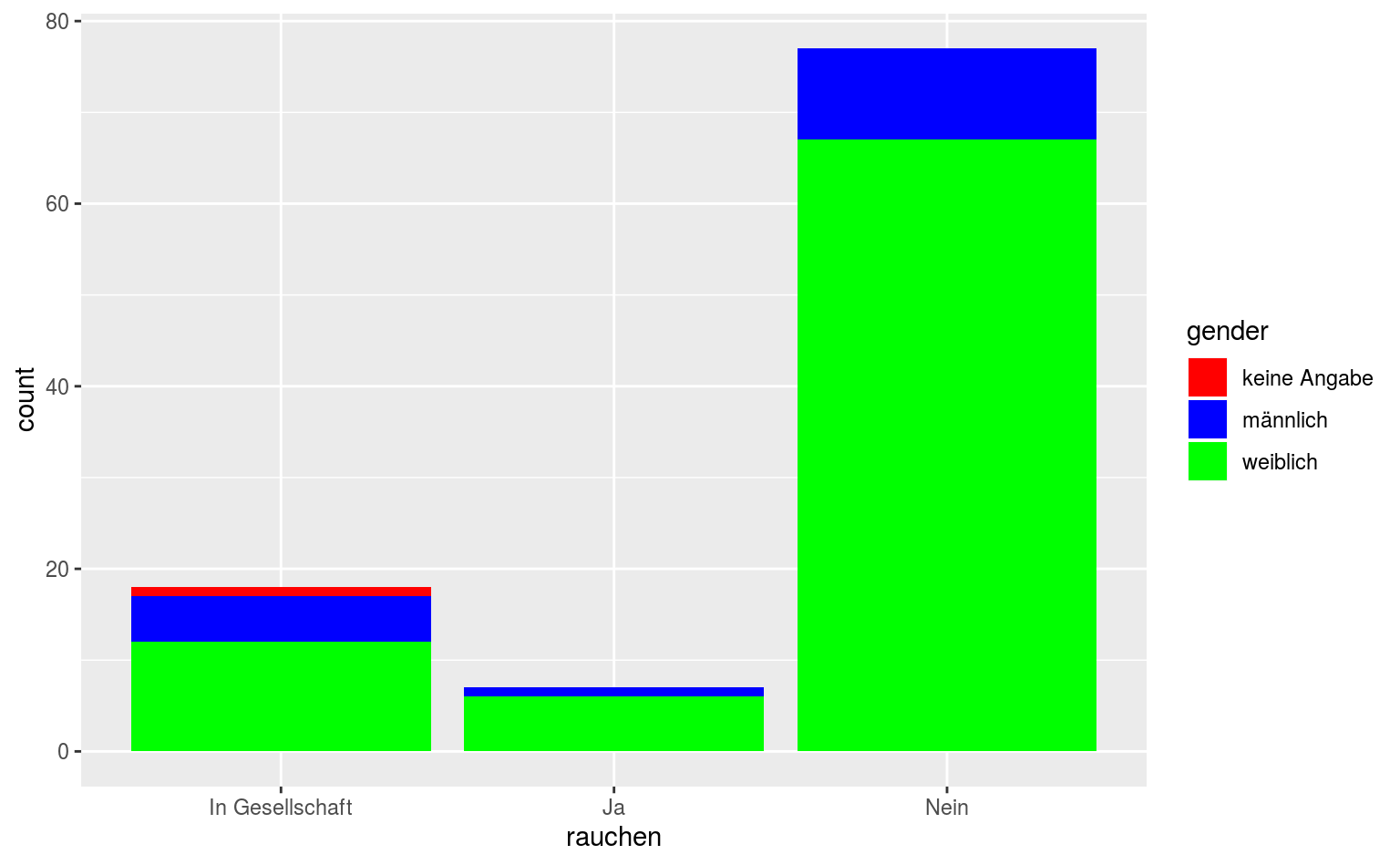
Oh glob, viel zu grell!
ggplot(data = qmsurvey, aes(x = rauchen, fill = gender)) +
geom_bar() +
scale_fill_manual(values = c("darkred", "lightblue", "darkgreen"))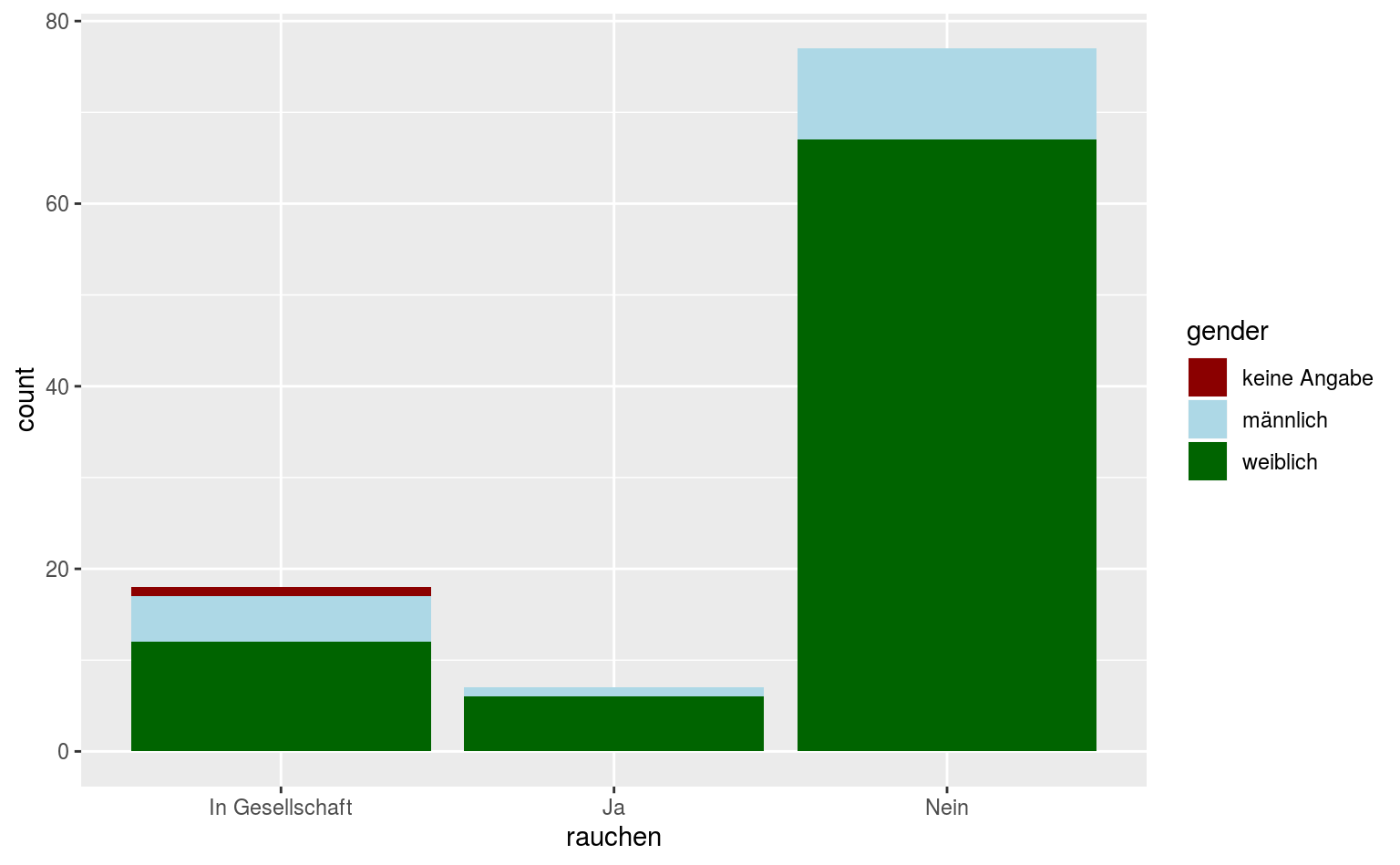
Besser, aber auch hässlich, nur anders.
Es stellt sich heraus, dass Farben kompliziert sind. Zumindest, wenn man Ansätze von ästhetischem Anspruch hat.
Zum Glück sind wir aber nicht auf manuelle Farbauswahl angewiesen, wir können fertige Farbpaletten benutzen, bei denen sich schonmal jemand Gedanken darüber gemacht hat, ob das okay aussieht oder nicht.
9.3.2 Zusätzliche Farbpaletten
9.3.2.1 RColorBrewer
# install.packages(RColorBrewer)
ggplot(data = qmsurvey, aes(x = rauchen, fill = gender)) +
geom_bar(position = "dodge", color = "black", alpha = .75) +
scale_fill_brewer(palette = "Set1")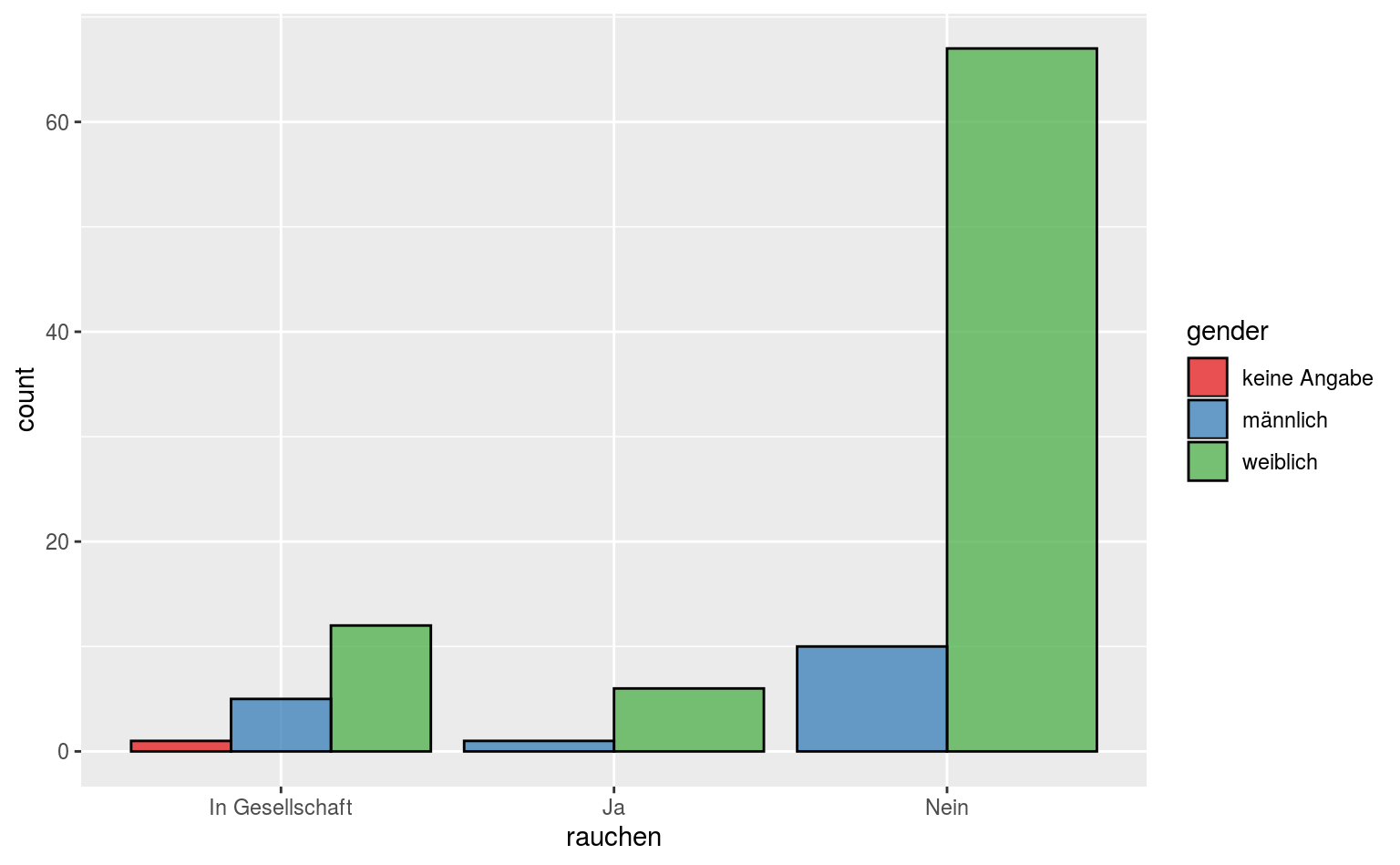
Übersicht über die Farbpaletten:
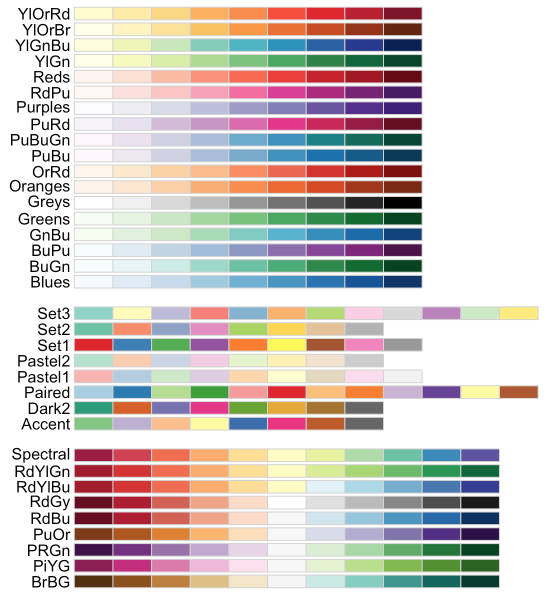
Abbildung 9.2: RColorBrewer Paletten
9.3.2.2 Viridis
Besondere Stärke: Gleicher wahrgenommener Abstand der Farben, demnach besonders gut geeignet für kontinuierliche Fabrskalen. Bonus: Auch noch gut distinguierbar, wenn in schwarzweiß konvertiert.
library(viridis)
ggplot(data = qmsurvey, aes(x = rauchen, fill = gender)) +
geom_bar(position = "dodge", color = "black", alpha = .75) +
scale_fill_viridis(discrete = TRUE, option = "plasma")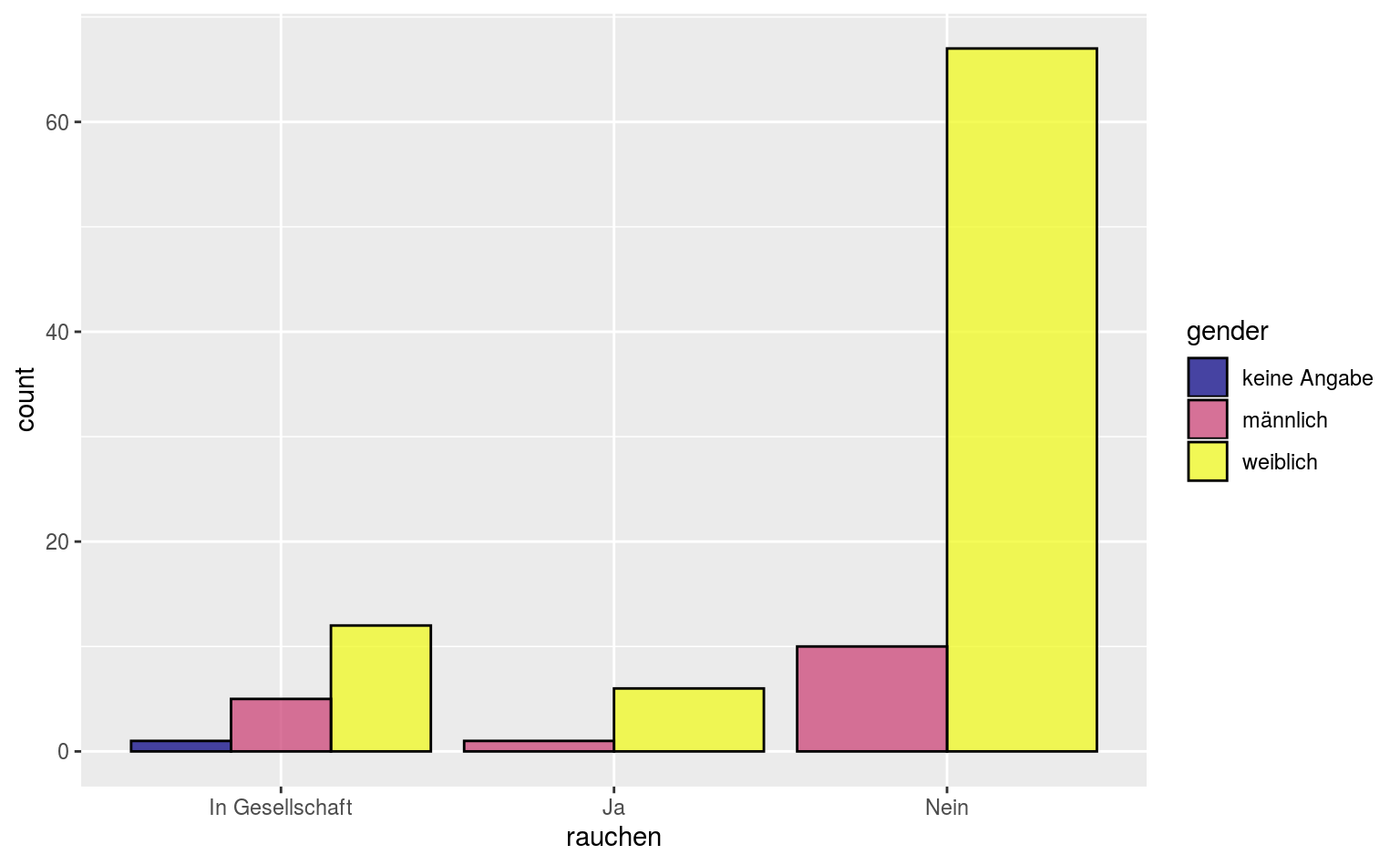
9.4 Themes
Themes verändern nicht die Farbe eurer Punkte/Linien/Balken, aber sie verändern alles andere an eurem Plot, von der Hintergrundfarbe bis zur Schriftart in den Labels.
Es gibt viele schöne themes, aber der allgemeine Ratschlag bleibt: Simpel ist besser.
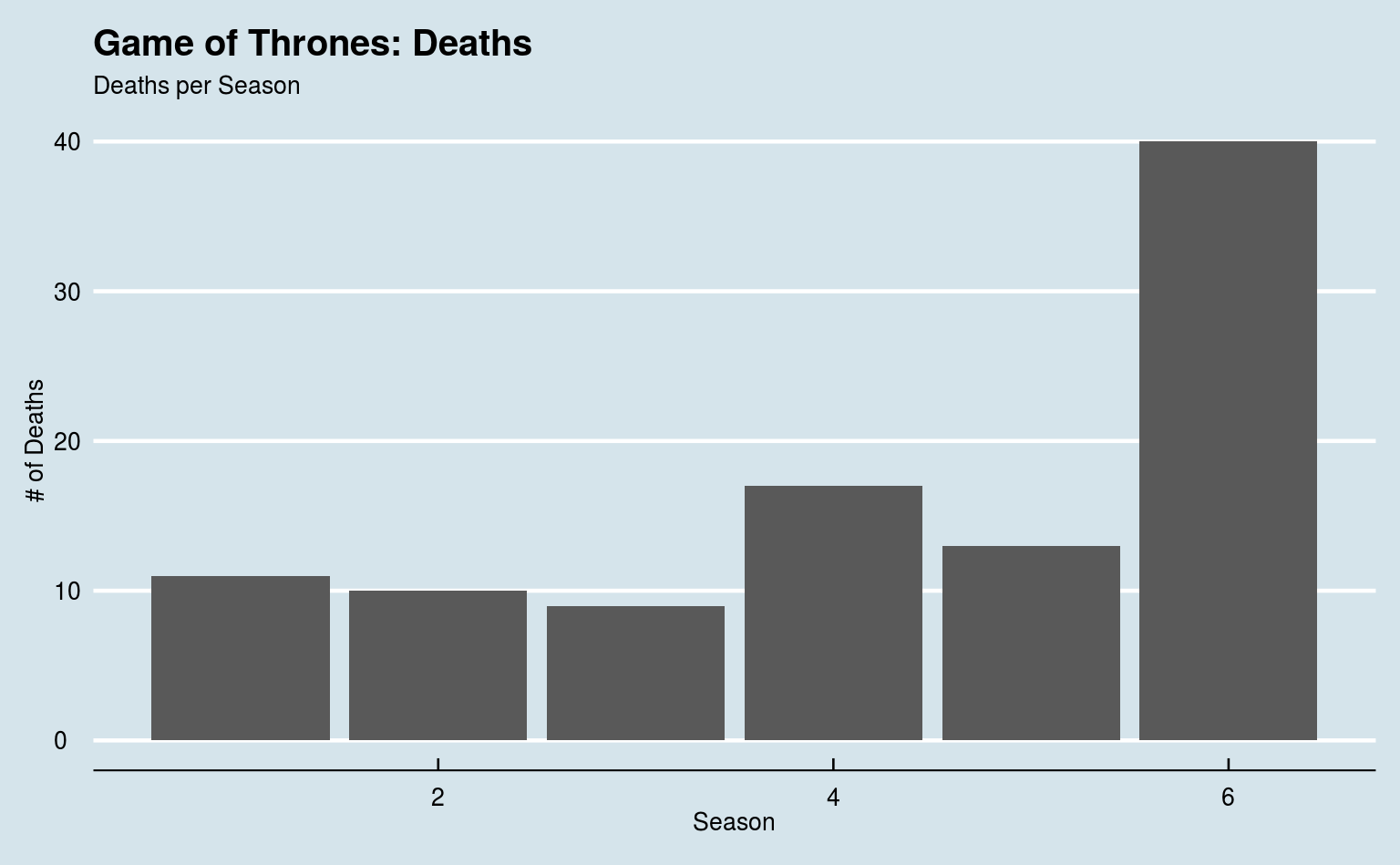
plot <- ggplot(data = gotdeaths, aes(x = death_season)) +
geom_bar() +
labs(title = "Game of Thrones: Deaths",
subtitle = "Deaths per Season",
x = "Season", y = "# of Deaths")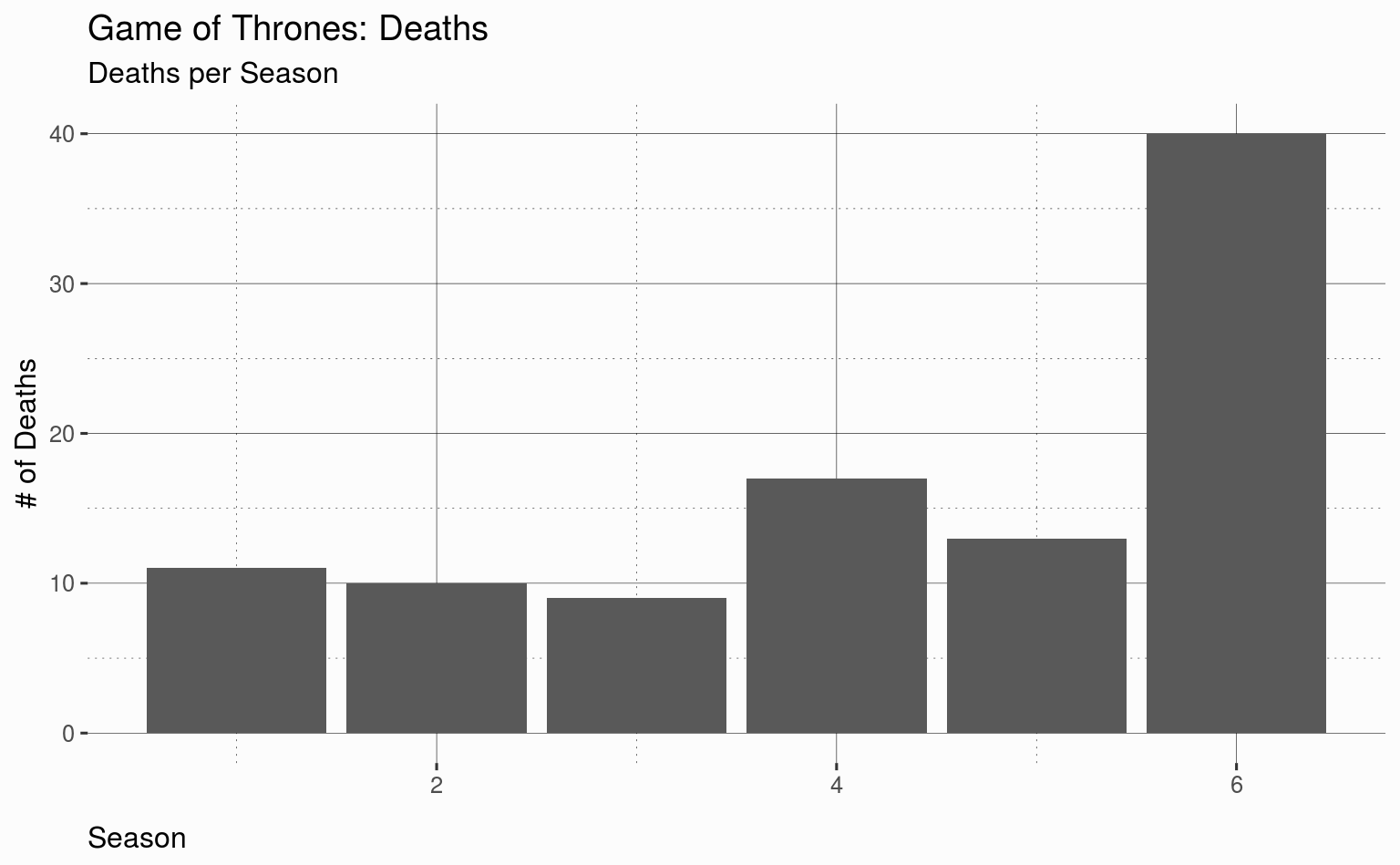
Oder auch:
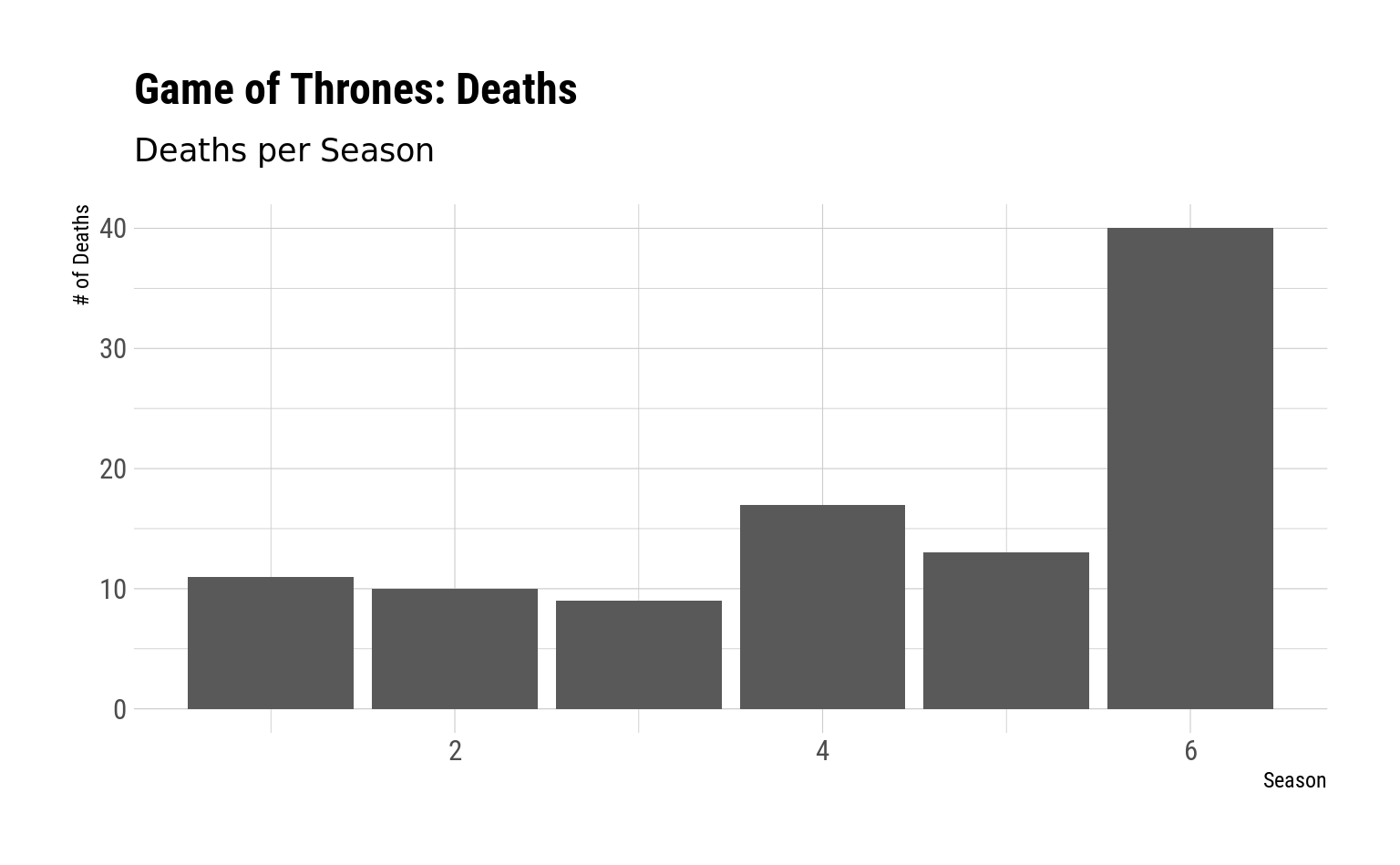
Siehe auch: ggthemes
9.5 Learning by Fiddleing
ggplot2 zu lernen lohnt sich sehr, weil ihr nach einer Weile einfach ein intuitives Gefühl dafür bekommt, wie ihr Daten eim schnellsten und einfachsten schön präsentieren könnt.
Der Weg dahin ist voller Googlereien und ihr werde viel Zeit damit verbringen Code von anderen zu copypasten und solange daran herumzuspielen bis es so grob das macht, was ihr wollt.
Also: Googlet was ihr machen wollt, und bookmarkt ggplot2.tidyverse.org.
Zusätzlich gibt es da noch diese unheimlich praktische Liste gängiger Anwendungsfälle:
http://r-statistics.co/Top50-Ggplot2-Visualizations-MasterList-R-Code.html.
Sucht euch den Code raus, der so grob macht was ihr wollt, und dann… happy tweaking.