Kapitel 8 Datenimport
Im Laufe eures Studiums (und vermutlich darüberhinaus) werdet ihr sehr viel Zeit damit verbringen Daten aus verschiedenen Quellen in die Statistiksoftware eurer Wahl (oder auch nicht eurer Wahl, aber der eurer Arbeitstselle) zu quetschen.
Das funktioniert mal mehr und mal weniger einfach, denn je nachdem wie die Originaldaten aussehen, kann das mitunter anstrengend bis deprimierend werden.
Saubere (tidy) Daten sehen immer gleich aus, aber unsaubere Daten sind alle auf ihre eigene Art unsauber. Mal fehlen Variablenbeschriftungen, mal sind da Umlaute durch Encoding kaputtgegangen, manchmal werden numerische Werte als character interpretiert und manchmal sind fehlende Werte mit irgendwelchen willkürlichen Werten kodiert (z.B. -99 anstatt NA).
Vielleicht wundert ihr euch auch, wieso dieses Kapitel erst so spät in dieser Einführung auftaucht. Das liegt primär daran, dass ihr unter Umständen ein ausreichend großes Repertoire an Grundlagen braucht, um Daten auf alle Fälle sauber eingelesen zu bekommen.
In vielen Fällen, und besonders in QM, ist das Ganze noch relativ überschaubar und eure TutorInnen können entsprechende Hilfestellung bieten, aber irgendwann seid ihr auf euch allein gestellt, und dann macht ein bisschen Bonus-Wissen hier und da den Unterschied zwischen einem anstrengenden Nachmittag voller Leid und Schmerz oder 10 Minuten Probiererei und schnellem Erfolg.
Wenn ihr Daten von eurer Festplatte einlesen wollt, und ihr keine Ahnung habt wie Dateipfade funktionieren, was euer Home Ordner ist, was beispielsweise ~/Documents sein soll oder wie ihr rausfindet, wo ihr gerade auf euren Computern seid, dann lest euch das bitte selber an.
Auch hier liefert RStudio jedenfalls im “Files”-Tab entsprechende Orientierungshilfe:
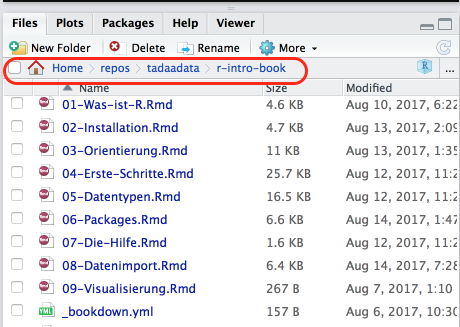
Abbildung 8.1: RStudio Filebrowser im Projekt dieser Einführung
Das rot umrandete ist der Pfad zum Projektordner, in R würde ich den also so eingeben müssen:
Wobei die Tilde ~ eine Abkürzung für das Home-Verzeichnis ist.
8.1 Quellen
Da in QM nur SPSS und R benutzt werden, werdet ihr vermutlich meistens auf Datensätze aus SPSS (.sav) stoßen. R kann zwar SPSS-Daten einlesen, aber SPSS kann mit R-Daten nichts anfangen. Außerdem beinhalten SPSS-Datensätze auch ein bisschen Metadaten, wie zum Beispiel Labels für eure Variablen oder nominalskalierte Variablen, die wir in R dann für bessere Optik benutzen können — andere Formate wie Textdateien (.csv, .txt, plain text) sind spartanischer und haben sowas nicht.
Die einfachste Option ist meistens die RStudio-Funktio zum Datenimport, aber auch hier solltet ihr erstmal wissen, wo eure Daten herkommen und ggf. über die ein oder andere Eigenart bescheid wissen.
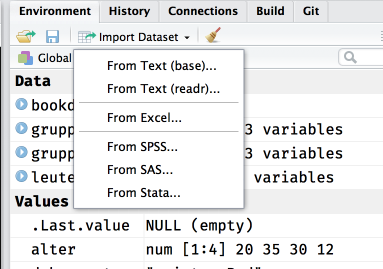
Abbildung 8.2: RStudio Import-Tool
Bei den Textdateien sind mit base und readr die beiden unterschiedlichen Möglichkeiten gemeint, mit denen wir Daten einlesen können, aber mehr dazu im entsprechenden Abschnitt.
Eine Sache noch zum Encoding: Um kaputte Umlaute und andere Krämpfe zu vermeiden bietet es sich an, überall alles immer auf Unicode bzw. UTF-8 zu stellen wenn ihr irgendwo nach Encoding gefragt werdet.
8.1.1 Roher Text (.csv, .txt)
- Benötigte packages:
readr - Anstrengend? Entweder alles super oder Riesenkrampf
Einfacher Text (plain text) ist die einfachste Möglichkeit Datensätze zu speichern bzw. zu übertragen, da Text so ziemlich der kleinste gemeinsame Nenner jeder gängigen Software ist. CSV heißt auch nur “comma separated values”, und wird euch vermutlich noch häufiger begegnen. Eine CSV-Datei könnt ihr mit jedem beliebigen Texteditor öffnen (ihr müsst dafür kein Office rauskramen, auf Windows tut es auch das Notepad), und ihr seht dann vermutlich sowas in der Art:
"extra","group","ID"
0.7,"1","1"
-1.6,"1","2"
-0.2,"1","3"
-1.2,"1","4"
-0.1,"1","5"
3.4,"1","6"Das Prinzip ist ziemlich einfach: In der ersten Zeile stehen die Variablennamen, und in jeder folgenden Zeile steht jeweils der Wert der zugehörigen Variable, getrennt durch ein Komma.
Die Schwierigkeit kommt dann, wenn die Werte zum Beispiel Text enthalten, der wiederum ein Komma enthalten kann, und der Wert nicht richtig in Anführsungszeichen gesetzt ist. Es gibt auch noch Varianten mit Tabs statt Kommata als Trennzeichen, das wäre dann strenggenommen TSV (ihr dürft raten wofür das T steht).
Textformate sind also ziemlich einfach um eure Daten zu speichern oder zu verschicken, aber es ist auch sehr fragil, sobald mal irgendwo ein " fehlt oder zu viel ist, wird’s kompliziert.
Zum lesen und schreiben empfehle ich herzlichst das readr-package mit den Funktionen read_csv, write_csv etc. zu benutzen, die sind weniger anfällig für Murks als die base-Standardfunktionen mit gleichem Namen aber . statt _ (read.csv, write.csv).
Als Beispiel laden wir mal diesen schönen Game of Thrones-Datensatz:
Hier habe ich col_types = cols() nur benutzt, um das Output zu unterdrücken. Ihr könnt über dieses Argument aber auch manuell spezifizieren, welchen Typ jede Spalte haben soll, damit eure Daten explizit so eingelesen werden, wie ihr sie erwartet.
Die schmutzigen Details gibt’s natürlich in der Hilfe: ?read_csv und online.
8.1.2 SPSS (.sav)
- Benötigte packages:
havenodersjmisc - Anstrengend? Manchmal.
Die Funktionen read_sav und read_spss sind identisch.
8.1.3 R (.rds, .rda & .RData)
- Benötigte packages: Keins (Base R reicht, optional
readrals Alternative) - Anstrengend? Nope, alles tutti.
Der wohl einfachste und dankbarste Anwendungsfall: Von R zu R.
Hier habt ihr zwei Möglichkeiten: .rds und .rda (auch .RData): Generell scheint .rds die präferierte Option zu sein.
8.1.3.1 .rds
Daten einlesen ist simpel:
#> # A tibble: 102 x 60
#> id gender alter geschwister zufrieden ueberfluessig selbsterfahrung
#> <int> <fct> <int> <int> <int> <int> <int>
#> 1 11 weibl… 19 1 4 2 2
#> 2 14 weibl… 25 2 4 2 1
#> 3 15 weibl… 19 1 4 3 2
#> 4 16 weibl… 21 1 5 2 1
#> 5 17 weibl… 19 1 5 2 4
#> 6 18 weibl… 25 1 4 3 2
#> 7 22 weibl… 19 1 2 2 5
#> 8 23 weibl… 20 3 3 4 2
#> 9 25 weibl… 19 3 3 3 2
#> 10 26 männl… 24 1 3 3 4
#> # … with 92 more rows, and 53 more variables: statistik <int>,
#> # tutorium <int>, lernen <dbl>, arbeit <dbl>, berufsvorstellung <int>,
#> # feiern <dbl>, socialnetworks <dbl>, alkohol <ord>, rauchen <fct>,
#> # cannabis <ord>, gefallen <int>, freundeskreis <int>, freundeeng <int>,
#> # orientierung <fct>, ons <fct>, partnerinnen <int>, bstatus <fct>,
#> # beziehungen <int>, bdauer <int>, sportstunden <dbl>,
#> # sportwichtig <int>, instrument <fct>, musik_SQ001 <int>,
#> # musik_SQ002 <int>, musik_SQ003 <int>, musik_SQ004 <int>,
#> # musik_SQ005 <int>, musik_SQ006 <int>, musik_SQ007 <int>,
#> # musik_SQ008 <int>, musik_SQ009 <int>, musik_SQ010 <int>,
#> # musik_SQ011 <int>, musik_SQ012 <int>, musik_SQ013 <int>,
#> # musik_SQ014 <int>, musik_SQ015 <int>, musik_SQ016 <int>,
#> # musik_SQ017 <int>, ernaehrung <fct>, dusche <fct>, telefonieren <int>,
#> # todesstrafe <fct>, demo <ord>, partei <fct>, parteiother <fct>,
#> # psyche <int>, behandlung <fct>, traeume <int>, schlafstunden <dbl>,
#> # morgens <int>, religion <int>, aussehen <int>Wir benutzen hier das tibble package nur, damit der Datensatz kompakter angezeigt wird. Das ist für euch keine Notwendigkeit, aber ich empfehle es in der Regel gerne, weil euch so nicht die Konsole vollgeklatscht wird, wenn ihr euch euren Datensatz mal schnell anschauen wollt.
Daten speichern auch:
Hier zum Beispiel der Datensatz zur Tutoriumsteilnahme, den ihr von https://public.tadaa-data.de/data/participation.rds runterladen könnt:
Alternativ könnt ihr das readr-package benutzen. Die Funktion daraus sieht fast gleich aus, und macht auch exakt das gleiche wie readRDS. Der einzige Grund für read_rds ist die Konsistenz der Funktionsnamen.
8.1.3.2 .rda, .RData
Nein, ihr benutzt nicht save und load für einzelne Datensätze.
Bei .rda bzw. .RData-Dateien ist zu beachten, dass diese den Namen des Objekts gleich mitspeichern, das heißt ihr müsst den eingelesenen Datensatz keinen Namen geben — der kommt schon mit der Datei.
Theoretisch kann so eine Datei auch mehrere Variablen enthalten, und wenn ihr zum Beispiel RStudio schließt und wieder öffnet, dann werden in der Zwischenzeit auch eure Variablen der aktuellen Session in Form einer .RData-Datei im Projektordner abgelegt und beim nächsten Start wieder eingelesen.
Speichern:
8.1.4 Excel (.xlsx)
- Benötigte packages:
readxl - Anstrengend? Manchmal. Aber wenn, dann richtig.
Wenn ihr ein sauberes (i.e. ohne Schnickschnak) Spreadsheet habt in dem auch wirklich nur eure Werte drinstehen, dann ist das Ganze recht simpel und ihr seid mit readxl auch gut bedient.
Wenn ihr einen dreckigen Haufen dampfender Menschenverachtung vor euch habt, dann… viel Spaß.
Es gibt da das ein oder andere Projekt für die komplexeren Fälle, aber wenn ihr die Möglichkeit habt, macht es euch so einfach (und rechteckig) wie möglich.
8.1.5 Google Sheets
- Benötigte packages:
googlesheets - Anstrengend? Meistens geht’s ganz gut.
Wenn euch Excel zu unpraktisch ist, dann bietet sich Google Sheets an. Es ist kostenlos, einfach und ausreichend mächtig für alles, was ihr so vorhaben könnten — mitunter weil ihr für alle komplexeren Sachen sowieso R benutzen wollt. Sheets ist praktisch wie Excel, nur halt in der CloudTM und von Google, aber für überschaubare Datensammlungen reicht’s auf alle Fälle. Die Tutoriumsteilnahmedaten haben wir da auch gesammelt, und da das Sheet immer an der selben Stelle ist muss man einfach nur den Code zum einlesen und auswerten erneut ausführen und schon hat man eine mehr oder weniger selbstupdatende Analyse. Nett.
In besagtem Projekt sieht das zum Beispiel so aus:
participation_1 <- gs_title("Tutoriumsteilnehmer") %>%
gs_read(ws = "WS1516", range = cellranger::cell_cols(1:7))Zuerst müsst ihr aber die Authentifizierung mit eurem Google-Account abhandeln:
Mit diesem Befehl zeigt euch das package all eure Google Sheets an nachdem es euch nach einem Login gefragt hat, von da aus könnt ihr dann weiterarbeiten. Mehr Informationen und Beispiele gibt’s in der Vignette.
8.2 Daten angucken & sauber machen
Happy families are all alike; every unhappy family is unhappy in its own way.
— Leo Tolstoy
and every messy data is messy in its own way - it’s easy to define the characteristics of a clean dataset (rows are observations, columns are variables, columns contain values of consistent types). If you start to look atreal life data you’ll see every way you can imagine data being messy (and many that you can’t)!
— Hadley Wickham (answering ‘in what way messy data sets are messy’) R-help (January 2008)
Um festzustellen, ob eure frisch eingelesenen Daten auch brauchbar sind, empfiehlt sich ein Blick in die Daten via View(daten) bzw. Über einen Klick auf den Datensatz im Environment-Tab von RStudio (das da oben rechts).
Zusätzlich ist auch hier natürlich str() praktisch, um zum Beispiel schnell zu überprüfen, ob eure Variablen auch alle die Klasse haben, die ihr erwartet (alle Zahlen sind numeric und Nominaldaten sind factor oder wenigstens character).
Es gibt da kein one-size-fits-all Rezept zur Datenbereinigung, denn jeder Datensatz ist auf seine eigene Art dreckig. Ihr könnt nur darauf hoffen, dass euer konkreter Anwendungsfall gut googlebar ist, oder ihr sowas ähnliches schonmal gemacht habt.
Die gängigsten Probleme sind recoding, umbenennen oder zusammenfassen, und das meiste lässt sich entweder mit dplyr, sjmisc oder ggf. tidyr erledigen. Versucht es erstmal innerhalb des tidyverse, das ist vermutlich angenehmer als zusammengehackte Google-Lösungen. Aber auch hier, wie gesagt: Je nachdem was ihr vorhabt. Mehr dazu findet sich in Data Munging.
Datenbereinigung ist entweder sehr einfach oder sehr komplex, oder irgendwo dazwischen. In diesem Sinne: Learning by example und so.
8.2.1 Der NGO Datensatz
Der NGO-Datensatz aus dem Kähler ist seit längere der default Übungsdatensatz und dementsprechend auch unfassbar langweilig für VeteranInnen. Zudem haben wir den Datensatz in sauber auch schon in der tadaatoolbox, das heißt, wenn ihr die toolbox ladet könnt ihr ngo direkt benutzen.
In der Vorlesung schwirrt darüberhinaus vermutlich eine SPSS (.sav)-Version des Datensatzes rum, die wir hier mal beispielshalber einlesen und bearbeiten, bis sie identisch zur tadaatoolbox-Version ist.
#> # A tibble: 6 x 17
#> IDNR JAHRGANG GESCHL STUNZAHL HAUSAUF ABSCHALT LEISTUNG BEGABUNG URTEIL
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 4 1 1 36 2 2 7 6 6
#> 2 51 1 1 35 2 1 2 4 5
#> 3 3 1 1 35 4 2 6 5 6
#> 4 1 1 1 30 3 2 6 5 5
#> 5 5 1 1 36 4 2 5 6 6
#> 6 6 1 1 35 3 1 3 8 5
#> # … with 8 more variables: ENGLISCH <dbl>, DEUTSCH <dbl>, MATHE <dbl>,
#> # ZENG <dbl>, ZDEUTSCH <dbl>, ZMATHE <dbl>, INDEX <dbl>, LEIST <dbl>Zuerst wollen wir mal die Variablen rauskicken, die wir nicht brauchen. In diesem Fall sind das die Variablen, die wir zu Übungszwecken sowieso selber erstellen wollen: ZENG, ZDEUTSCH, ZMATHE, INDEX, LEIST
#> # A tibble: 6 x 12
#> IDNR JAHRGANG GESCHL STUNZAHL HAUSAUF ABSCHALT LEISTUNG BEGABUNG URTEIL
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 4 1 1 36 2 2 7 6 6
#> 2 51 1 1 35 2 1 2 4 5
#> 3 3 1 1 35 4 2 6 5 6
#> 4 1 1 1 30 3 2 6 5 5
#> 5 5 1 1 36 4 2 5 6 6
#> 6 6 1 1 35 3 1 3 8 5
#> # … with 3 more variables: ENGLISCH <dbl>, DEUTSCH <dbl>, MATHE <dbl>Besser. Als nächstes stört mich, dass die Variablennamen alle UPPER CASE sind. Ich will die alle in lower case haben. Dafür können wir die Funktion tolower benutzen.
#> # A tibble: 6 x 12
#> idnr jahrgang geschl stunzahl hausauf abschalt leistung begabung urteil
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 4 1 1 36 2 2 7 6 6
#> 2 51 1 1 35 2 1 2 4 5
#> 3 3 1 1 35 4 2 6 5 6
#> 4 1 1 1 30 3 2 6 5 5
#> 5 5 1 1 36 4 2 5 6 6
#> 6 6 1 1 35 3 1 3 8 5
#> # … with 3 more variables: englisch <dbl>, deutsch <dbl>, mathe <dbl>Besser. Als nächstes wollen wir unsere Variablen labeln, zum Beispiel soll geschl nicht 1 oder 2 sagen, sondern Männlich und Weiblich.
# Falls NA noch nicht korrekt kodiert:
ngo$hausauf <- ifelse(ngo$hausauf == 0, NA, ngo$hausauf)
ngo$abschalt <- ifelse(ngo$abschalt == 0, NA, ngo$abschalt)
ngo$geschl <- factor(ngo$geschl, labels = c("Männlich", "Weiblich"))
ngo$jahrgang <- factor(ngo$jahrgang, labels = c("11", "12", "13"), ordered = TRUE)
ngo$abschalt <- factor(ngo$abschalt, labels = c("Ja", "Nein"))
head(ngo)#> # A tibble: 6 x 12
#> idnr jahrgang geschl stunzahl hausauf abschalt leistung begabung urteil
#> <dbl> <ord> <fct> <dbl> <dbl> <fct> <dbl> <dbl> <dbl>
#> 1 4 11 Männl… 36 2 Nein 7 6 6
#> 2 51 11 Männl… 35 2 Ja 2 4 5
#> 3 3 11 Männl… 35 4 Nein 6 5 6
#> 4 1 11 Männl… 30 3 Nein 6 5 5
#> 5 5 11 Männl… 36 4 Nein 5 6 6
#> 6 6 11 Männl… 35 3 Ja 3 8 5
#> # … with 3 more variables: englisch <dbl>, deutsch <dbl>, mathe <dbl>Besser.
Hier haben wir jahrgang auch gleich zu einem ordered factor gemacht, damit die Reihenfolge der Merkmalsausprägungen immer intakt bleibt. Gegebenenfalls müssen wir das beachten, falls wir damit mal ’ne ANOVA machen wollen, aber erstmal finden wir das so gut.
Zusätzlich solltet ihr beachten, dass Umlaute wie das ä in Männlich zwar auf eurem Computer lokal kein Problem sein sollten, solange ihr euch immer brav an UTF-8 haltet, aber Windows handhabt Dinge da leider etwas anders als Linux und macOS, von daher könnte es sinnvoll sein für "Männlich" lieber "M\\u00e4nnlich" einzusetzen. Das ist der selbe Text, allerdings mit explizitem Unicode-Encoding. Es gibt Funktionen wie stringi::stri_escape_unicode("Männlich"), die die Konvertierung für euch machen, aber ich wünsche euch, dass ihr euch nie im Detail damit befassen müsst.
Als nächstes können wir noch value labels setzen, die dann in sjPlot-Plots und Tabellen angezeigt werden. Bei unseren frisch erstellten factor-Variablen ist das nicht mehr nötig, aber hausauf könnte welche gebrauchen:
library(sjlabelled)
ngo$hausauf <- set_labels(ngo$hausauf,
labels = c("gar nicht", "weniger als halbe Stunde",
"halbe Stunde bis Stunde", "1 bis 2 Stunden",
"2 bis 3 Stunden", "3 bis 4 Stunden",
"mehr als 4 Stunden"))
ngo$hausauf#> [1] 2 2 4 3 4 3 3 3 3 NA 1 1 3 2 3 4 4 5 3 4 2 4 4
#> [24] 3 3 6 4 3 4 4 3 2 3 2 5 3 4 3 4 4 2 3 4 3 3 3
#> [47] 3 3 3 3 5 2 4 4 6 6 3 4 4 5 5 4 4 3 3 5 2 3 3
#> [70] 4 4 4 3 3 4 4 3 4 4 4 4 3 3 3 7 3 3 4 4 3 3 7
#> [93] 4 2 3 1 4 5 3 4 3 2 2 4 1 4 3 4 4 4 2 2 3 3 3
#> [116] 3 3 4 5 3 3 3 5 3 2 4 3 2 4 4 1 4 4 3 2 3 4 4
#> [139] 3 2 3 3 4 2 2 3 3 3 2 4 3 4 2 4 5 6 3 2 2 1 4
#> [162] 4 3 2 2 3 2 4 2 NA 4 4 3 3 4 3 2 2 2 4 4 3 4 5
#> [185] 2 2 4 3 1 2 3 3 4 3 2 4 3 4 3 NA 1 3 2 3 NA 1 4
#> [208] 3 3 3 4 1 1 3 3 3 4 3 3 3 4 3 3 4 3 4 4 5 4 4
#> [231] 4 4 4 5 4 4 6 5 4 3 5 3 3 2 4 4 2 1 3 5
#> attr(,"labels")
#> gar nicht weniger als halbe Stunde halbe Stunde bis Stunde
#> 1 2 3
#> 1 bis 2 Stunden 2 bis 3 Stunden 3 bis 4 Stunden
#> 4 5 6
#> mehr als 4 Stunden
#> 7Als letztes können wir noch ein paar Variablen-Labels verteilen:
ngo$geschl <- set_label(ngo$geschl, "Geschlecht")
ngo$abschalt <- set_label(ngo$abschalt, "Abschalten")
ngo$jahrgang <- set_label(ngo$jahrgang, "Jahrgang")
ngo$hausauf <- set_label(ngo$hausauf, "Hausaufgaben")…Wir könnten noch mehr Labels verteilen, aber das sind so die Variablen, die am ehesten in Kontingenztabellen auftauchen, von daher reicht mir das so.
Fertig.
Sauber.
Wenn ihr den Datensatz so als Datei wegspeichern wollt, geht das einfach mit:
Der ganze Code zum Saubermachen in einem großen Blob:
library(haven)
library(sjlabelled)
library(tibble)
library(dplyr)
# Einlesen
ngo <- read_sav("data/NGO.SAV")
# Variablen rauskicken
ngo <- ngo %>%
select(-ZENG, -ZDEUTSCH, -ZMATHE, -INDEX, -LEIST)
# Variablennamen in lower case
names(ngo) <- tolower(names(ngo))
# Recoding
# Falls NA noch nicht korrekt kodiert:
ngo$hausauf <- ifelse(ngo$hausauf == 0, NA, ngo$hausauf)
ngo$abschalt <- ifelse(ngo$abschalt == 0, NA, ngo$abschalt)
ngo$geschl <- factor(ngo$geschl, labels = c("Männlich", "Weiblich"))
ngo$jahrgang <- factor(ngo$jahrgang, labels = c("11", "12", "13"), ordered = TRUE)
ngo$abschalt <- factor(ngo$abschalt, labels = c("Ja", "Nein"))
# Value labelling
ngo$hausauf <- set_labels(ngo$hausauf,
labels = c("gar nicht", "weniger als halbe Stunde",
"halbe Stunde bis Stunde", "1 bis 2 Stunden",
"2 bis 3 Stunden", "3 bis 4 Stunden",
"mehr als 4 Stunden"))
# Variable labelling
ngo$geschl <- set_label(ngo$geschl, "Geschlecht")
ngo$abschalt <- set_label(ngo$abschalt, "Abschalten")
ngo$jahrgang <- set_label(ngo$jahrgang, "Jahrgang")
ngo$hausauf <- set_label(ngo$hausauf, "Hausaufgaben")
# Speichern als Datei
saveRDS(ngo, "ngo.rds")